

NLP Haber Bülteni’nin 11. sayısına hoş geldiniz. Bu sayıda vergi politikası tasarımı için takviyeli öğrenme (İng. reinforcement learning) framework’leri, kabul görmüş en güncel (SotA) AI sohbet sistemleri ve metin üretme araçlarını geliştirme gibi konu başlıklarını işlemekteyiz.
dair.ai sitesinden güncellemeler
- Metin tabanlı duygu araştırmada kullanılabilecek bir veri seti yayımladık. Repo, duygu sınıflandırma (İng. emotion classification) görevi için ön-eğitime tabi tutulmuş BERT modellerine nasıl ince-ayar yapılacağını gösteren bir Colab notebook‘u içermektedir. Kısa süre önce bir NLP işlem dizisine (İng. pipeline) kolayca entegre edilebilecek bir modele veri setimiz üzerine ince-ayar yapılmıştır ve Huggingface’te erişilebilmektedir.
- Kısa süre önce ilk kez yaptığımız bildiri okuma oturumumuzu gerçekleştirdik. 120’den fazla kişinin kayıt olduğu ve çoğunun uzak etkinliğimize katılım gösterdiği oturumumuzun ilk tartışma konusu T5 bildirisi üzerine oldu. Bildirinin derinlemesine tartışmasını yapacağımız ikinci bir oturuma da ev sahipliği yapacağız. Herkes şuradan erişilebilen etkinliğimize davetlidir. Gelecek etkinlikler hakkında daha fazla bilgi sahibi olmak için Meetup grubumuza ya da Slack kanalımıza katılabilirsiniz. Ayrıca gelecek etkinlikler hakkında bilgileri NLP Haber Bülteni’ne 🔖 abone olarak da alabilirsiniz.
Araştırma ve Yayınlar 📙
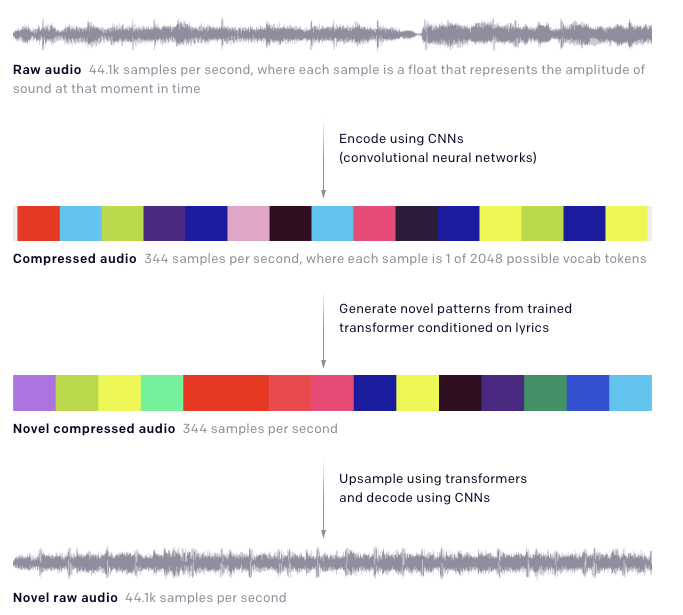
OpenAI’nın Jukebox’ı
Çeşitli türlerde ve artistik tarzlarda (sıfırdan) müzik üretmek için eğitilen sinir ağı yapısı olan Jukebox, OpenAI’nın en son çalışmalarından biridir. VQ-VAE olarak adlandırılan niceleme-tabanlı (İng. quantization-based) yaklaşımdan esinlenilmiş model, tür, artist ve şarkı sözü girdileri ile beslenmekte ve yeni bir ses örneği üretmektedir. Ana fikir, çok-seviyeli bir otokodlayıcı (İng. autoencoder) ile uzun, işlenmemiş ses girdilerini işleyip sıkıştırmak ve gerekli müziksel bilgiyi muhafaza ederek boyutları indirgemektir. Ardından, transformatörler (İng. transformer) VQ-VAE kod çözücüsü (İng. decoder) tarafından kullanılarak ham sesi yeniden yapılandıracak kodları üretmek için kullanılmaktadır. Çalışmayla ilgili daha fazla detayı şu blog gönderisinde ya da bildiride bulabilirsiniz.
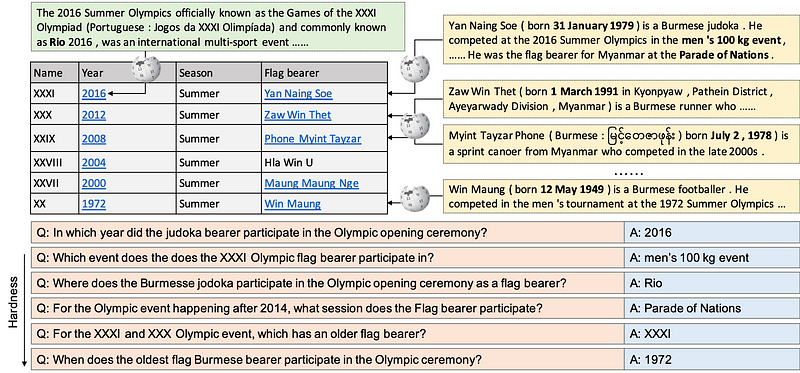
HybridQA: Çizelge ve Metin Verisi üzerine Çok-Sekmeli Soru Cevaplama Veri Seti
Şimdiye kadar çoğu soru-cevap (QA) veri seti türdeş bilgilere odaklanmıştır. HybridQA, farklı cinsten bilgiler üzerinde akıl yürütmeyi gerektiren araştırmaları ve yöntemleri teşvik etmek için oluşturulmuş büyük ölçekli bir soru-cevap veri setidir. Çok-sekmeli QA veri seti, yapılandırılmış bir Vikipedi tablosu ve tablodaki serbest çalışma derlemelerine bağlı yapılandırılmamış varlıklardan oluşmaktadır. Ayrıca, yazarlar yalnızca tabloyu ya da metni kullanmanın aksine farklı cinsten bilgilerle çalışmanın avantajlarını ön plana çıkardıkları iki adet taban çalışmayı da tartışmaktadırlar; ancak sonuçların insan performansının çok arkasında kaldığını ve bu durumun da farklı cinsten veri üzerinde daha iyi akıl yürütmeyi beceren ve kapsam sorunlarını ele alan QA sistemlerine bir çağrıda bulunduğunu belirtmektedirler.
Bir SotA Sohbet Robotu
Facebook AI, gelmiş geçmiş en büyük açık alanlı sohbet robotu olarak bahsettikleri AI tabanlı modelleri Blender’i inşa etti ve açık-kaynaklı yaptı. Meena‘nın (Google tarafından sunulan bir konuşkan AI sistemi) başarısını takiben, Facebook AI, kaliteli konuşmalar üretmek için empati ve kişilik gibi sohbet yeteneklerini harmanlayan bir model önermektedir. Model, yaklaşık 1.5 milyar eğitim örneği üzerinde Transformatör tabanlı bir model (9.4 milyara kadar parametresi olan) kullanılarak eğitilmiştir. Ardından modelin konuşma becerilerini geliştirebilecek tanımlanmış, arzu edilen kişisel özellikleri kazandırmayı amaçlayan Blended Skill Talk veri seti üzerine ince-ayar yapılmıştır. Yazarlar, modelin insan değerlendirmeciler tarafından Meena’nın ürettiklerinden daha insanca kabul ettikleri cevaplar üretebildiğini iddia etmektedirler.
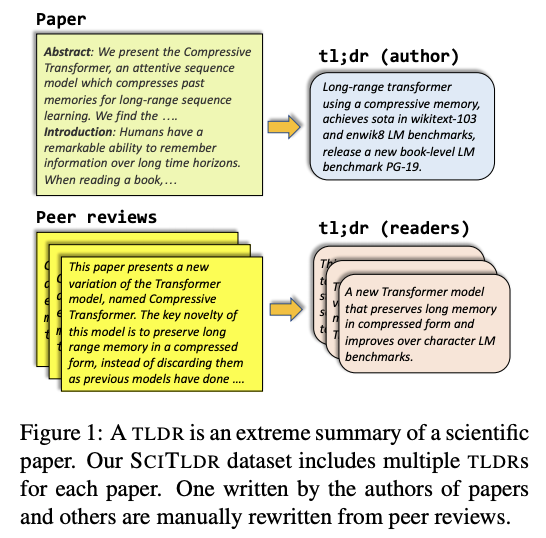
TLDR: Bilimsel Dokümanların Aşırı Özetlenmesi
Şu bildiri, yeni bir görev olan bilimsel bildirilerin TLDR’sinin üretilmesi (İng. TLDR generation) için yeni bir yaklaşım ile birlikte veri seti (SCITLDR) önermektedir. TLDR’ler bilimsel makalelerin yoğun özetleri ve bir alternatif olarak tanımlanmaktadır. TLDR’ler, yazarlar tarafından önerildiği üzere bir bildirinin ne hakkında olduğunu hızlıca anlama yolu olarak hizmet edebilmekte ve okuyucuya bildiriyi okumaya devam edip etmemeye karar vermesinde yardımcı olabilmektedir. İnsan üretimi özetlerin çeşitliliğinden dolayı çoklu TLDR’ler hakemlerden değerlendirme yoluyla elde edilmektedir. Çoklu-görev ince ayar programı (başlık üretimi ve TLDR üretimini içermektedir) olan BART-tabanlı bir model nihai görev için kullanılmıştır.
Not: TLDR, too long, didn’t read söyleminin kısaltması olup “çok uzundu, okumadım” anlamına gelmektedir ve genellikle uzun dokümanların sonunda kısaca dokümanın ne anlattığını birkaç cümlede anlatan kısmı işaretlemek için kullanılır.
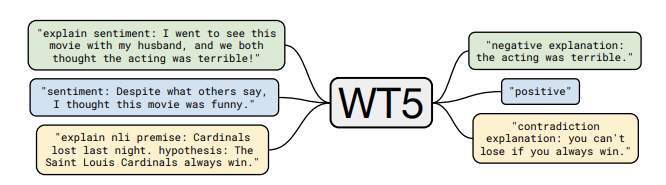
WT5?! Tahminlerini Açıklamak için Metinden-Metine Modellerin Eğitimi
Metinden-metine Aktarım Transformatörü (İng. Text-to-Text Transfer Transformer) (T5), NLP öğrenme aktarımı (İng. transfer learning) alanındaki en son gelişmeleri tek ve birleşik bir framework olarak bir araya getirme yöntemidir. Bu çalışma, hem girdilerin hem de çıktıların metin olduğunu varsayarak birçok NLP görevinin metinden-metine biçiminde formüle edilebileceğini ileri sürmektedir. Yazarlar, bu “framework’un hem ön-eğitim hem de ince-ayar için tutarlı eğitim hedefleri sağladığını” iddia etmektedirler. T5, aslında özellikle modelin dikkat (İng. attention) bileşenlerine yapılmış çeşitli geliştirmeleri uygulayan kodlayıcı-kod çözücü (İng. encoder-decoder) Transformatördür. Model, yeni yayımlanan Colossal Clean Crawled Corpus veri seti üzerinde ön-eğitime tabi tutulmuştur ve özetleme, soru cevaplama ve metin sınıflandırma (İng. text classification) gibi NLP görevlerinde kabul görmüş en güncel (İng. state-of-the-art) sonuçlara ulaşmıştır.
T5’i takip eden yeni bir çalışma, WT5 (-Why, T5?-“Neden, T5?”in kısaltması), Transformatör tabanlı T5 modelini kendi yaptığı tahminlere açıklama üretmesi için ince ayar yapmıştır. Bu da modelin neden belirli tahminleri yaptığının daha iyi anlaşılmasına yardımcı olabilmektedir. Model, yalnızca hedef açıklamalı ve hedef etiketli örneklerle beslenmektedir. Bir görev ön eki (örneğin duygu) olan girdi metin ve asıl metin de önüne eklenmiş “explain(açıkla)” etiketi alabilmektedir (aşağıdaki resimde örnek görebilirsiniz). Bu da modele, tamamen etiketlenmiş veri ve açıklama etiketleri bulunan sınırlı sayıda örneği sağlayarak yarı-gözetimli (İng. semi-supervised) öğrenmeyi aktif etmektedir. Yazarlar, yaklaşımlarının alan dışı veri üzerinde iyi sonuç ürettiğini ve açıklanabilirlik veri seti üzerinde kabul görmüş en güncel niteleyici ve sayısal sonuçlarını bildirmişlerdir. Bu çalışma, metin-tabanlı modellerin tahminlerini daha iyi anlamak için kullanılabilecek ilgi çekici bir temel model sunmaktadır; ancak yazarlar yaklaşımın yorumlanabilirliğin yalnızca yüzeysel bir gelişmesi olduğunu ve daha ilerletilebileceğini vurgulamaktadırlar.
Narang et al. (2020)
Araçlar ve Veri Setleri ⚙️
NVIDIA’nın Tıbbi Görüntüleme Framework’u
MONAI, sağlık alanında bilimsel gelişmeleri desteklemek için geliştirilen bir tıbbi görüntüleme AI framework’udur. Yayımlama notlarında bildirildiği üzere, MONAI sağlık hizmet verisi ile başa çıkabilmek için kullanıcı dostu ve alana optimize bir kütüphane sağlamayı hedeflemektedir. Benzer diğer kütüphaneler gibi ayrıca alana özel veri işleme ve dönüştürme araçları, bu alanda yaygın kullanılan sinir ağı modelleri ve değerlendirme yöntemlerine erişim ve sonuçları yeniden üretebilme yetenekleri sağlamaktadır.
Python Game Boy Emülatörü
PyBoy, Python’da yazılmış ve Game Boy donanımı ile çalıştığı makine arasına arabirim kurmaya yardımcı olan bir araçtır. İçerisinde oyun ile etkileşime geçen AI tabanlı bir ajanın (İng. agent) eğitilebilmesi için deneysel bir ortam da bulunmaktadır.
PDF olarak Jupyter Notebook’ları
Hiç notebook’larınızı düzgünce bir PDF haline getirmek istediniz mi? Tim Head tarafından yazılan şu Jupyter uzantısı eklenti bakımından en az gereksinimle notebook’unuzdan PDF üretmenize ve yeniden üretilebilirlik için notebook’larınızı PDF’lere ekleyebilmenize olanak sağlamaktadır.
Daha Gerçekçi Konuşkan AI Sistemleri Üzerine
Transformers, artık kütüphanedeki ulaşılabilen ilk konuşkan (İng. conversational) tepki modeli olan DialoGPT‘ye erişimi içermektedir. DialoGPT, Microsoft tarafından önerilen büyük ölçekli, konuşkan, cevap üreten bir modeldir. Vikipedi ve haber gibi metin verilerine bağlı olan önceki modellerden farklı olarak Reddit yorumlarından çıkarılan çok miktardaki karşılıklı konuşmaları kullanmaktadır. DialoGPT, yanıt üretmek için büyük ölçekli bir ön-eğitim sağlamayı hedefleyen GPT-tabanlı özbağlanımlı (İng. autoregressive) dil modelidir ve konuşkan AI’nın insan etkileşimini daha iyi temsil etmesine yol açmaktadır.
TorchServe ve [Kubernete için TorchElastic], büyük ölçekte model eğitmek ve servis etmek için yeni PyTorch kütüphaneleri
TorchServe, geliştiricilerin süreçte zorlanmalarını azaltmayı hedeflerken modellerini eğitme ve servis etmelerine olanak sağlayan açık-kaynaklı bir kütüphanedir. Bu araç PyTorch’un üzerine inşa edilmiş olup geliştiricilerin modellerini job olarak AWS üzerinde çalıştırmalarına izin vermektedir. Torchserve’nin kolay uygulama, temiz sonuç çıkarım API’leri, raporlama, gerçek zamanlı sonuç servisi metrikleri ve kolay model yönetimi gibi yetenekleri eğitilmiş modellere sunmak için kabul görmüş bir yol olması beklenmektedir.
MLSUM: Çok Dilli Özetleme Derlemi (The Multilingual Summarization Corpus)
NLP’de çok dilli çalışmaları teşvik etmek ve güçlendirmek amacıyla Thomas Scialom ve diğer araştırmacılar kısa süre önce çok dilli özetleme derlemini sundular. Veri seti, gazetelerden elde edilmiş olup Fransızca, Almanca, İspanyolca, Rusça ve Türkçe yaklaşık 1.5 milyon makale içermektedir.
ML ile Yapıldı (Made with ML)
Eğer kaçırdıysanız, Goku Mohandas, ilgili ve ilginç ML projelerini keşfedebileceğiniz bir araç sağlamayı hedefleyen Made with ML isimli internet sitesini geliştirdi. Kullanıcıların topluluk ile projelerini paylaşabilecekleri bir platform niteliğindedir. Siteye en son eklenen yeniliklerden birisi de kullanıcılara ilgili projeleri hızlıca bulmada yardımcı olan seçilmiş konular bölümüdür.
Makaleler ve Blog Gönderileri ✍️
ICLR 2020 Konferansında Transformatörler için hangi yenilikler var?
Makine öğrenmesinde birincil konferanslardan ICLR, tüm dünyadaki seyahat kısıtlamaları sebebiyle bu yıl sanal olarak yapılmak zorunda kaldı. Zirve konferanslardan olmak her zaman büyük çalışmaların beklentisi içerisinde olmak demektir; özellikle söz konusu, çığır açmış geçmiş çalışmaların üzerine yapılan geliştirmeler olduğunda. Örneğin, Transformatörler birçok NLP görevinde kabul görülen en güncel sonuçları üretmeyi başarmışlardı ve ICLR’de bu modelleri geliştirmek için yollar öneren iki adet çalışma kabul edildi.
Şu makale, yapısal revizyonlar (ALBERT, Reformer ve Transformer-XH gibi), yeni öğrenme prosedürleri (ELECTRA ve Pretrained Encyclopedia gibi) ve büyük ölçekte çıkarım, metin üretimi, görsel-dilbilimsel temsiller gibi diğer alanlarda geliştirmeler içeren Transformatörler’le ilgili çalışmaları özetlemektedir. İlginç bir bildiri, Transformatör yapılarının, potansiyel bir CNN genelleştirmesi olduğunu öne süren ilginç bulgularıyla, konvolüsyon ile öz-dikkat(İng. self-attention) katmanlarının ortak yönlerini açıklayan detaylı bir analiz sağlamaktadır.
Eğer bu yıl ICLR’de yayımlanan diğer çalışmalar hakkında daha çok bilgiye sahip olmak isterseniz, Papers with Code sitesine göz gezdirebilirsiniz.
ICLR bütün konferans konuşmalarını kullanıma açmış bulunmaktadır.
AI Ekonomisti: AI-Destekli Vergi Politikaları ile Eşitlik ve Üretkenliği Artırmak
Takviyeli öğrenme (İng. reinforcement learning), AI laboratuvarlarının AI alanında çığır açan gelişmeler yapmalarına olanak sağlamaktadır. AI sistemleri ile özellikle vergi politikası tasarımı gibi küresel problemlerle başa çıkma amacıyla, bir grup araştırmacı sadece simülasyon ve veriye bağlı çözümler kullanarak dinamik vergi politikalarını öğrenmeyi amaçlayan takviyeli öğrenme frameworku AI Economist‘i sundular. AI Economist’ten elde edilen bazı gelişmeler umut verici sonuçlar göstermekte ve bu da onu sosyal çıkarları ve ekonomik eşitsizliğin mevcut durumunu geliştirebilecek bir framework olma potansiyeline sahip yapmaktadır.

AI sistemlerine sağduyulu akıl yürütme kabiliyetleri getirmek üzerine
Günümüz AI sistemlerinin birçoğunun sağduyulu akıl yürütme yeteneklerinde eksiklik olduğu tartışılmaktadır. Şu detaylı makale bu problemin kısa bir tarihini ve en son teknolojiler üzerinde çalışan araştırmacıların bu alanda nasıl ilerleme kaydettiklerini anlatmaktadır. Beklenildiği üzere güncel çalışmaların birçoğu, bir bilgi tabanı inşa ederek sinir ağlarına (özellikle dil modellerine) dünyayı daha hızlı ve efektif anlamayı öğretmektedirler. Bu, kapsam ve hassaslık problemleri ile baş etmek için sembolik akıl yürütme ile sinir ağlarını birleştirme girişimi olarak düşünülebilir.
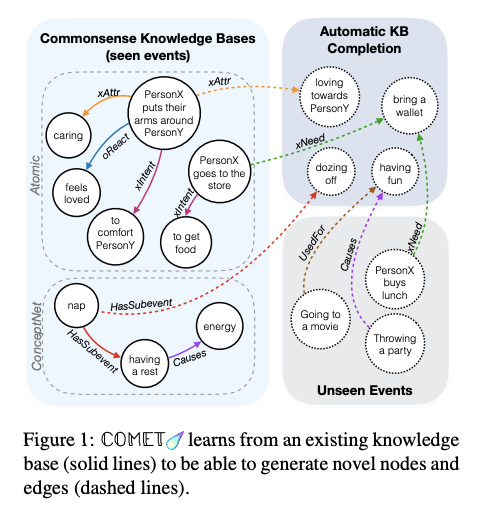
COMET — Bosselut et al. (2019)
BERT’lere ayak uydurmak: ana NLP başarım ölçütlerinin kritiği
NLP insanlardan daha iyi neler yapabilir ve hala geliştirilebilir mi? Güncel bir blog gönderisinde, Manuel Tonneau, GLUE ölçütleri üzerinde model performansını gözden geçirmekte ve hangi görevlerde NLP sistemlerinin başı çektiğini hangi görevler hala insanların daha üstün olduğunu belirlemektedir. SuperGLUE ve XTREME ölçütleri de çıtayı daha yukarı taşıma ve yeni görev ve yeni diller üzerindeki araştırmaları motive etme girişimi olarak sunulmuştur.
Transformatör Modelleri için Triton (TensorRT) Inference Sunucusunun Kıyaslaması
Şu detaylı blog gönderisi, üretimde kullanılacak Transformatör tabanlı dil modellerinin servis edilmesi için yapılan ilginç kıyaslama deneylerini ele almaktadır. Yazarlar, modelleri ve deneyleri farklı ayarlar ve seçeneklerle tutmak için NVIDIA’nın Triton (TensorRT) Inference Sunucusunu kullanmaktadırlar. Ayrıca TensorFlow ve PyTorch tabanlı modellerin karşılaştırılabilir sonuçlarını sağlamaktadırlar. Rapor, eşzamanlı servis gecikmesi, girdinin eşzamanlı serviste işlenme süresi ve yığın (İng. batch) ve sekans uzunluğu gibi diğer yapılandırma ayarlarıyla model servis etmenin farklı yönlerinden elde edilmiş sonuçları içermektedir. Model servis etmenin birçok yönü raporda bulunmamaktadır; ancak yazarlar model versiyonlamayı ve nesne tespiti gibi farklı görevleri test etmekle oldukça ilgililerdir. Bu tarz rehberler, insanların modellerini üretime koymalarına yardımcı olacak kıyaslama modelleri için en iyi yöntemleri ve teknikleri sağlamaktadır.
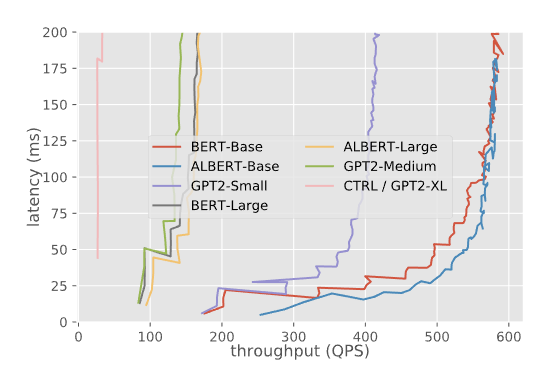
Farklı modellerin gecikme ve işleme süreleri — kaynak
Keras’ta Tekrarlayan Katmanlara Görsel Rehber
Amit Chaudhary’nin şu makalesi Keras’ta bulunan tekrarlayan katmanlara (İng. recurrent layers) ve girdi ve çıktıdaki çeşitli argümanların etkilerine görsel bir açıklama sağlamaktadır. Makalenin, veri hazırlarken ve işlerken Keras RNN katmanları ile nasıl etkileşime geçilmesi gerektiğini daha iyi anlamaya yardımcı olması amaçlanmaktadır. RNN modelleri ile dil modellemeye ilgisi olan yeni başlayanlar için faydalı bir rehberdir.
Eğitim 🎓
Bulut, Mobil & Uç Cihazlar için Pratik Derin Öğrenme Kitabı
Eğer derin öğrenme modellerinizi bulut, mobil ya da uç cihazlara (İng. edge device) taşımak gibi bir ilgi alanınız varsa Anirudh Koul, Siddha Ganju ve Meher Kasam tarafından yazılan şu kitaba göz gezdirebilirsiniz. Kitabın başlığı “Practical Deep Learning Book for Cloud, Mobile & Edge (Bulut, Mobil ve Uç Cihazlar için Pratik Derin Öğrenme Kitabı)”dır ve konu başlıkları bilgisayarla görü modellerinizi ayarlama ve uygulama, kırkın üzerinde endüstriyel kullanım alanlarına giriş ve modelleri hızlı eğitebilmek için öğrenme aktarımının (İng. transfer learning) kullanımı gibi konular üzerine yoğunlaşmıştır.

Makine öğrenmesi dersleri
- Stanford, Andrew Ng. tarafından verilen ML dersinin yeni kaydedilen videolarını erişilebilir hale getirdi. Bu ders, makine öğrenmesi dünyasına yeni başlayan öğrenciler için iyi hizmet edebilecek içerikler sağlamaktadır.
- ML ve NLP sistemlerini gerçek dünyada kullanmak için üretime geçirdikçe, daha güvenilir ve mahremiyeti koruyan sistemleri inşa etmek önemli bir hal almaktadır. Bu ders, güvenilir makine öğrenmesi alanındaki konu başlıklarını kapsamaktadır.
- Thomas Wolf, NLP’de öğrenme aktarımının en son akımları ve gelecek konu başlıklarını açıklayan şu kapsamlı video-tabanlı özeti yayımladı.
GAN’ları öğrenmek
Pieter Abbeel’in şu video dersi, gerçekçi resimler üretme ve dijital boyama gibi günümüzde her çeşit yaratıcı uygulamada kullanılan çekişmeli üretici ağlara (İng. generative adversarial networks) detaylı bir genel bakış sağlamaktadır. Bu ders, şu an UC Berkley’de öğretilen Derin Gözetimsiz Öğrenme (İng. Deep Unsupervised Learning) dersinin bir parçasıdır. Aşağıda dersin ana hatlarını görebilirsiniz.

Derin Öğrenme için Diferansiyel Hesaplama
Aurélien Geron, diferansiyel hesaplamanın türevler, kısmi türevler, gradyanlar gibi temel konseptlerini öğretmeyi amaçladığı ilginç Colab notebook‘unu paylaştı. Bu konu başlıkları derin öğrenme alanında oldukça yüksek önem taşımaktadırlar ve Geron bu başlıkları özetlemekte ve yol göstermek için anlaması kolay görselleştirmeler içeren implementasyonlarını açıklamaktadır. Ayrıca, oto-türev (İng. auto-differentiation) üzerine başka bir notebook‘a bakmayı da önermektedir.
Bunlara da göz atın ⭐️
- Andrej Karpathy, Tesla’da eksiksiz sürüş için çabalarına ilişkin AI teknolojilerindeki en yeni gelişmeleri paylaştı. Konu başlıkları HydraNet’in modellenmesi, veri motorları, değerlendirme ölçütleri ve bu büyük ölçekli sinir ağı modellerinden nasıl efektif bir şekilde sonuç alınabileceği gibi konulardan oluşmaktadır.
- MLT tarafından hazırlanmış, etkileşimli makine öğrenmesi, derin öğrenme ve matematik araçları içeren hoş bir repoya buradan erişebilirsiniz.
- Yeni bir bildiri, büyük NLP modellerinin eğitim maliyetlerine ve bu maliyetlerin nasıl değiştirilebileceğine dair kısa bir genel bakış sağlamayı hedeflemektedir.
- Kısa süre önce Springer, matematikten derin öğrenme başlıklarına kadar uzanan yüzlerce kitabı ücretsiz olarak erişime açtı. Şu makale ücretsiz indirmeye uygun olan bazı makine öğrenmesi kitapları özetlemektedir.
- Kra-Mania, Seinfeld dizisinden oluşturulan açık soru-cevap (QA) veri setini kullanarak Haystack (soru cevaplama ve arama için araç) ile yapılmış bir uygulamadır. Şu rehber bu kütüphane ile nasıl kolayca QA işlem dizilerinin inşa edilebileceğini göstermektedir. Ayrıca şu linkte uygulamayı deneyebilirsiniz.
- Açıklanabilirlik, araştırmacılar tarafından derin sinir ağlarını daha iyi anlamayı amaçlayan bir süreçtir. AI sistemleri gerçek dünyada kritik alanlarda kullanıldıkça açıklanabilirlik, önemli ve aktif bir araştırma alanı olmaktadır. Şu bildiri, deneyimsizler için derin öğrenme açıklanabilirliğine “alan kılavuzu” sağlamaktadır.
- ML ve NLP’de son zamanların popüler araştırma alanlarından birisi olan veri artırma (İng. data augmentation) üzerine olan çalışmaları açıklayan kısa bir derlemeye göz gezdirebilirsiniz.
- Bir önceki haber bülteninde, Transformatör’ün bir çeşidi olan ve özellikle uzun dokümanlarda olmak üzere çeşitli NLP görevlerinde başarımı artıran Longformer’dan bahsetmiştir. Şu videoda, Yannic Kicher bu çalışmanın önerdiği yeniliklere güzel bir açıklama getirmektedir.
Eğer NLP Haber Bülteni’nin bir sonraki sayısında paylaşmak istediğiniz tamamlanmış veri seti, proje, blog gönderisi, rehber ya da bildiriniz varsa, lütfen şu formu kulanarak direkt olarak gönderiniz.
NLP Haber Bülteni’nin gelecek sayılarını gelen kutunuzda görmek istiyorsanız 🔖 *abone olun*.