

Hello everyone! Welcome to the 13th issue of the NLP Newsletter. In this issue, we cover topics that range from interesting works presented at the ACL conference to tools for improving the exploration of papers and code to several useful NLP tool recommendations.
Special thanks to Keshaw Singh and Manikandan Sivanesan for significantly contributing towards this edition of the NLP Newsletter.
dair.ai updates
- In one of our upcoming talks, Dr. Juan M. Banda will discuss the motivation and rationale behind their Social Media Mining Toolkit (SMMT), and how to use it to define frameworks for large-scale social media data gathering for NLP and machine learning research projects. They will outline all the lessons learned, mistakes, and hard decisions made to produce and maintain a publicly available large-scale dataset of COVID-19 Twitter chatter data featuring over 424 Million Tweets in 60+ languages and from 60+ countries.
- We recently hosted a live stream talking about how to get started with NLP. If you are just getting started with NLP and you are looking for research tips feel free to check out the talk. We are hosting more live streams like this in the future, so if you want to get notified you can either subscribe to the YouTube channel or the Meetup page.
- In the upcoming paper discussion, we will discuss the paper titled “Deep Learning Based Text Classification: A Comprehensive Overview”.
Research and Publications 📙
Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
One of the most common strategies for measuring generalization in NLP models is via evaluation of held-out test sets. While useful, this approach has two significant drawbacks — overestimation of a model’s generalization capability, and the inability to determine its failure points. In a work presented at this year’s ACL (which also won the best paper award), Ribeiro et al. (2020) propose a more comprehensive evaluation methodology which is model-agnostic as well as task-agnostic.
It applies the behavioral testing principle of “decoupling testing from implementation” by treating the model as a black box, allowing comparison of different models trained on different data. The code, with the help of templates and other abstractions, allows users to generate a large number of test cases easily. The work also contains multiple user studies, demonstrating the effectiveness of this framework in identifying critical failure points in both commercial and state-of-the-art models.
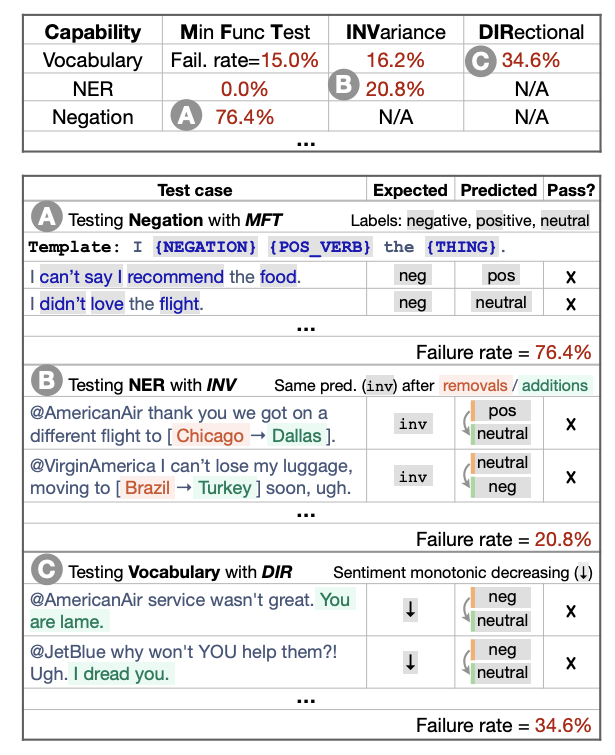
CheckListing a commercial sentiment analysis model (source)
TaBERT: A new model for understanding queries over tabular data
Most approaches today are mostly trained to learn from free-form language but not DB tables. TaBERT is the first model to support a joint understanding of natural language sentences and tabular data. This joint understanding of information across different data formats is important in areas such as question understanding where it would take a model the ability to semantically parse over databases to possibly address a query. TaBERT can enable different business use cases such as directly asking questions about a product where the answer exists in a particular e-commerce database of products or transactions.
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data
In another award-winning publication from this year’s ACL conference, professors Emily M. Bender and Alexander Koller advocate for a clear understanding of the distinction between form and meaning in contemporary NLP research. Focusing on the debate around whether large pretrained language models like BERT and GPT-2 “understand” language, they argue the following — “the language modeling task, because it only uses form as training data, cannot in principle lead to learning of meaning.” The paper also contains several insightful thought experiments, including one they call “the octopus test.” Finally, the authors call for a more top-down approach to future research in NLP, and propose some best practices on how to navigate the challenges that lie therein.
Tackling Climate Change with Machine Learning
Can we use machine learning methods to reduce greenhouse gas emissions? This recent paper looks at the landscape of ML methods for mitigating this issue and potentially tackling climate change. Besides providing a comprehensive survey of ML methods applied in different sectors (e.g., transportation, electricity systems, buildings and cities, etc. ) and specific problems (e.g., urban planning, optimizing supply chains, etc), the authors also provide recommendations, a call for collaboration, and business opportunities to tackle climate change.
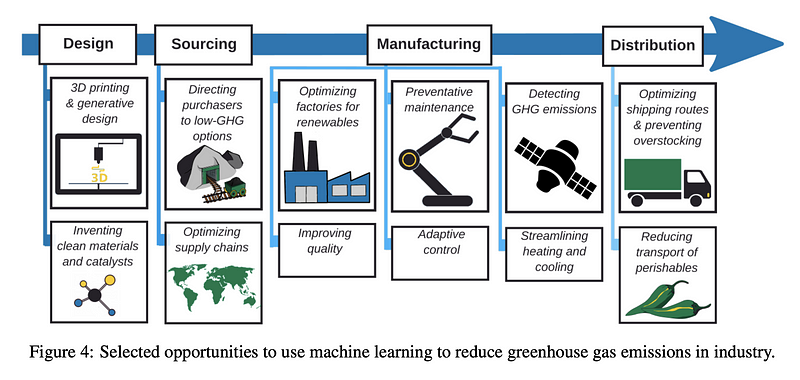
Figure by Rolnick et al. (2020)
Contextual Embeddings: When Are They Worth It?
Deep contextual embeddings like ELMo and BERT have found widespread use in industry in recent years, in addition to enabling rapid progress on several benchmarks like GLUE. Besides incurring significant costs in terms of time and memory while pretraining, there are additional costs during fine-tuning or inference on downstream tasks as well. In a work presented at the recently concluded ACL, Arora et al. (2020) assess the benefits of using BERT embeddings relative to non-contextual (GloVe, random) embeddings. Through their experiments on benchmark downstream tasks like named entity recognition (NER), sentiment analysis, and natural language understanding (GLUE) tasks, they show that it is often possible to get within 5–10% of absolute performance of BERT embeddings when using GloVe or random embeddings.
Defining and Evaluating Fair Natural Language Generation
Presented at the ACL 2020 Widening NLP Workshop, the work of Catherine Yeo and Alyssa Chen focuses on the biases that emerge in the language generation task of sentence completion. In particular, they introduce a mathematical framework of fairness for NLG followed by an evaluation of gender biases in GPT-2 and XLNet. Their analysis provides a theoretical formulation for defining biases in NLG and empirical evidence that existing language generation models embed gender bias.
Smart To-Do: Automatic Generation of To-Do Items from Emails
Many of us are familiar with the Smart Reply feature we see on our email applications. Mukherjee et al. (2020) explore a new way to boost user productivity, by automatically creating to-do lists from email threads. What differentiates this task from other language generation tasks (e.g. email conversation summarization, news headlines) is its action-focused nature, i.e., identifying specific task(s) to be performed.
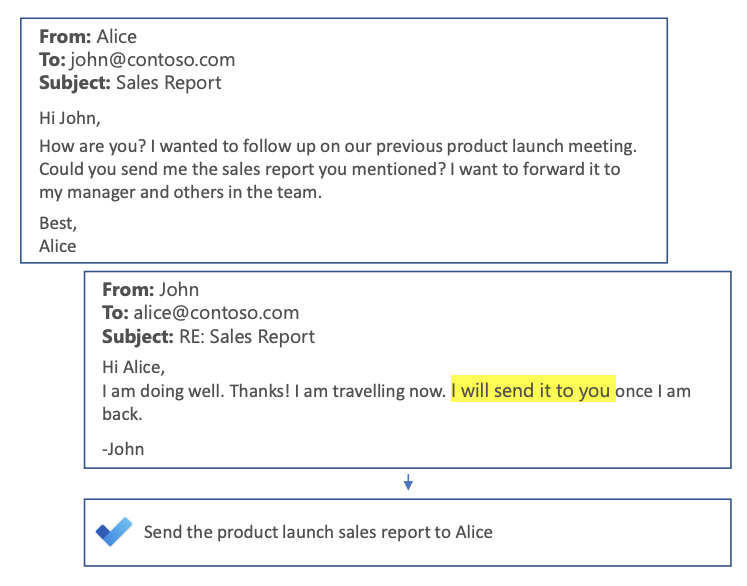
Sample To-Do list generation (source)
Tools and Datasets ⚙️
Transformer v3.0
The Hugging Face team has released a new version of their popular library called Transformers. In the new Transformers v3.0, they have improved documentation, improved tokenization capabilities, and offer several model improvements and additions.
Texthero
Texthero is a Python toolkit for working more efficiently with text-based datasets. It can be used by people getting started in NLP and who are seeking to quickly build a NLP pipeline to understand the data before modeling. This is also a great tool for teaching about NLP concepts since it offers a high-level API to easily and efficiently interact with textual datasets.
Papers with Code Methods
The Papers with Code team recently released a new feature called Methods that allows users to better search, navigate, and learn about the different building blocks of machine learning such as optimizers, activations, attention, and much more. With this feature, you can now easily find out what has been the progress, in terms of methods, in the field of NLP. You can even track the usage of these methods over time and what tasks they support.
Code Finder for Research Papers
This recently released free browser extension is useful for automatically finding and showing links to code implementations for ML papers anywhere on the web such as Google Search, Arxiv, Twitter, Scholar, and other sites.
Articles and Blog posts ✍️
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
Encoding the semantics of words and sentences is something we take for granted that state-of-the-art NLP systems are capable of. SentenceBERT provides illustrating examples of how we can make the best use of Transformer based architectures in tasks such as clustering and semantic textual similarity. This model is however limited to processing sequences of text from a single language, which in some cases can be the factor preventing you from deploying such a model into production. It would, therefore, be interesting to figure out a way to extend these models into the realm of multilinguality, which is what Reimers et al. study in their work titled “Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation”. This article provides a summary of this work, where Viktor Karlsson also shares his thoughts and reflections on the authors’ contribution and findings.
DeViSe on PyTorch
This blog post showcases the Deep Visual-Semantic (DeViSe) embedding model implemented in PyTorch. DeViSe uses word vectors of labels as the targets which facilitate the learning of the semantic meaning of the labels. The model is trained to identify the visual objects using labeled image data & semantic information from unannotated text. Such models can then be used to generate interesting results for tasks such as keyword search, image reverse search, and image to keyword search.
Discovering Protein Structure and Function Through Language Modeling
Transformer language models have shown to be very effective at encoding sequential information such as natural language sentences which is useful to build highly predictive models that perform a wide range of different NLP tasks. As Transformer models keep improving they have also seen adoption in other areas such as computer vision for object detection. It should come as no surprise that the underlying attention mechanism used in these language models can be applied effectively to other difficult and high impact problems such as discovering protein structure.
Recent work from a Salesforce research group shows the potential of using a Transformer language model to recover the high-level structure and functional properties of proteins by training the model to predict masked amino acids in a protein sequence. As this information can be processed sequentially, a similar BERT-based language model pretraining strategy can be used and applied to large scale unlabeled protein sequences. The attention mechanism is shown to capture contact relationships which could be useful for protein interaction prediction and fuel scientific discovery in Biology.
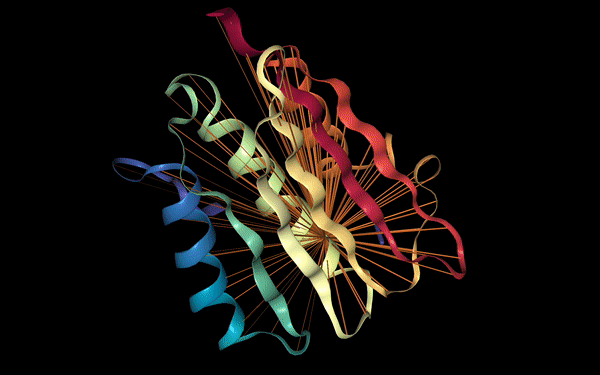
Figure source: Salesforce Einstein
Text Data Cleanup using Dynamic Embedding Visualisation
Having high-quality training data for machine translation tasks is paramount and is more challenging in the case of low resourced languages. In this blogpost, Morgan McGuire demonstrates how to use techniques such as multilingual contextual embeddings, along with dimensionality reduction using UMAP to interactively identify noisy clusters and remove them to improve the datasets. The following animation showcases a random noisy cluster containing Arabic and website footer data in an Irish-English dataset.
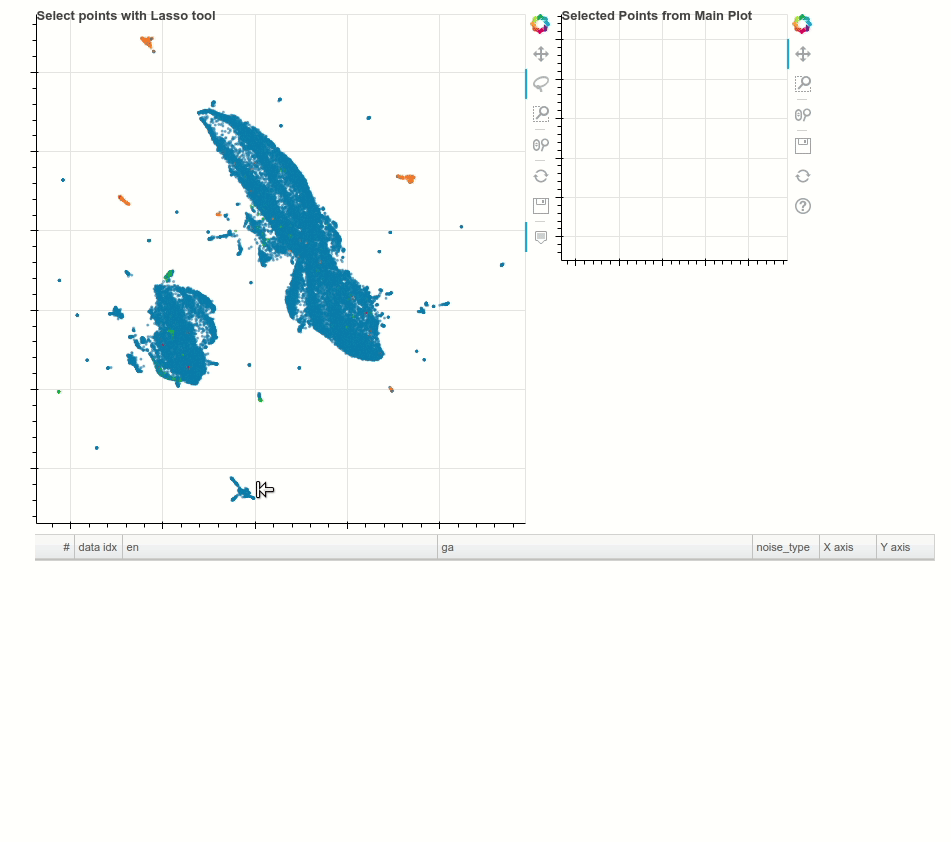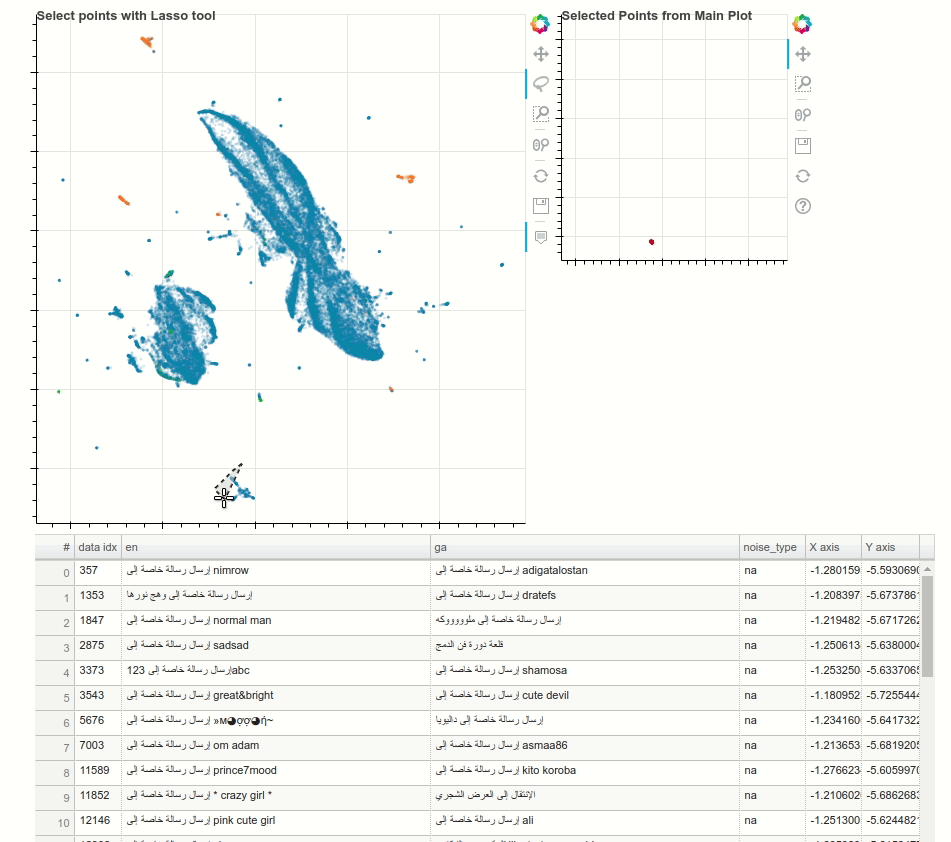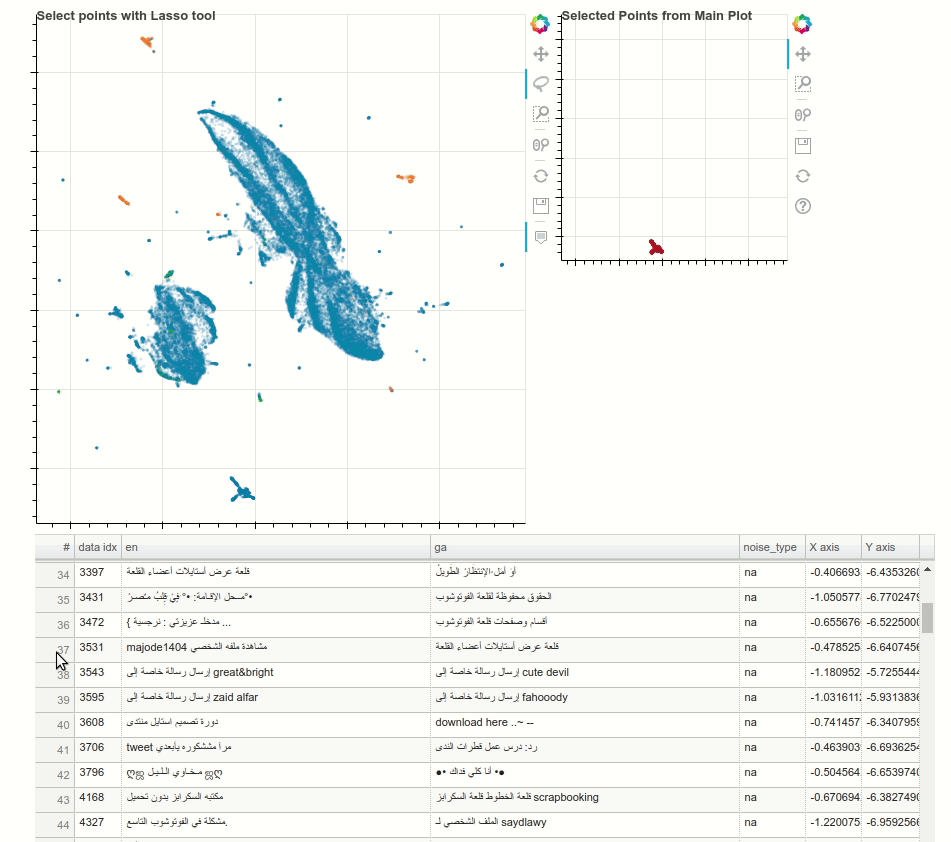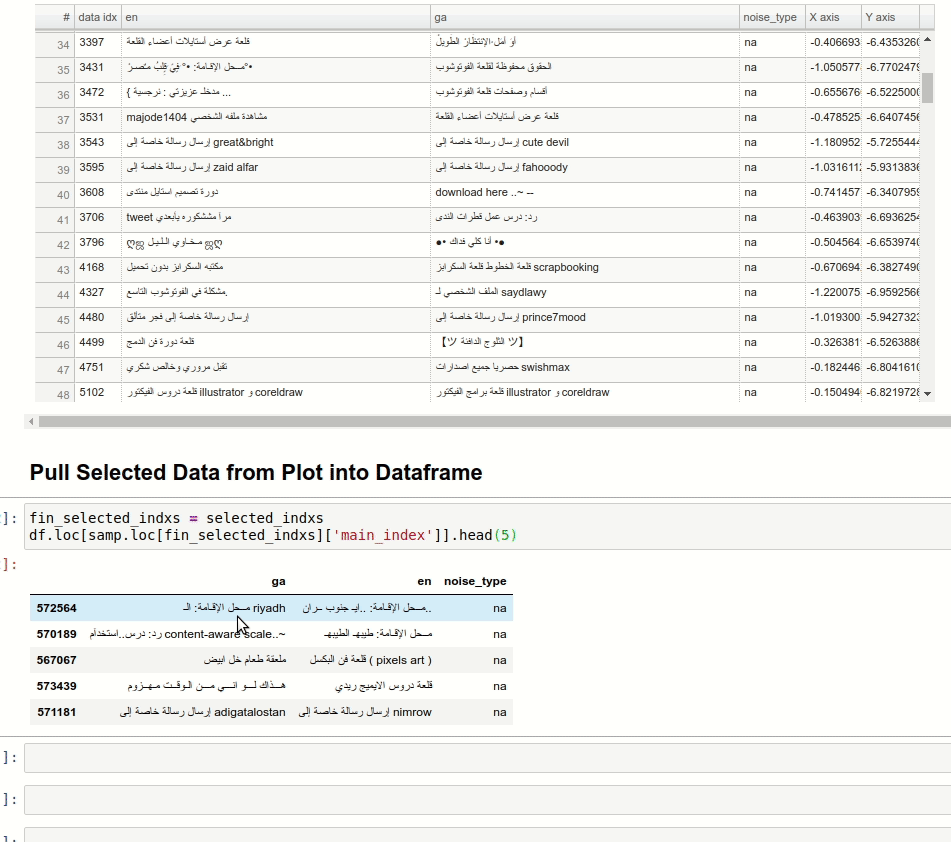
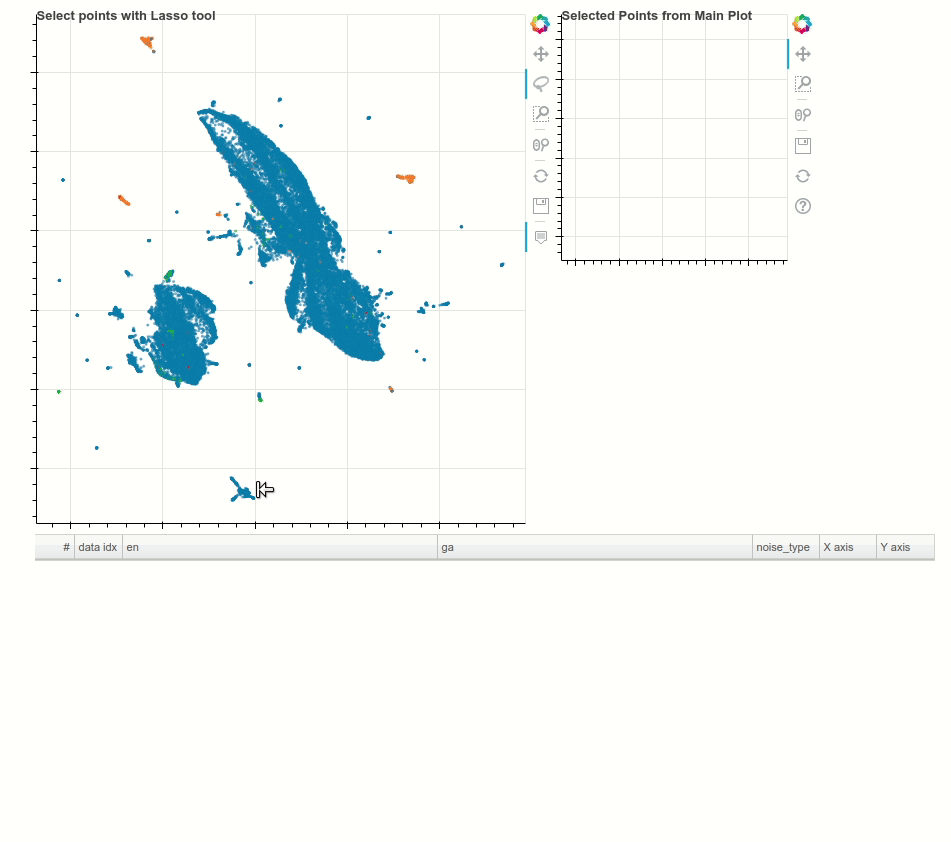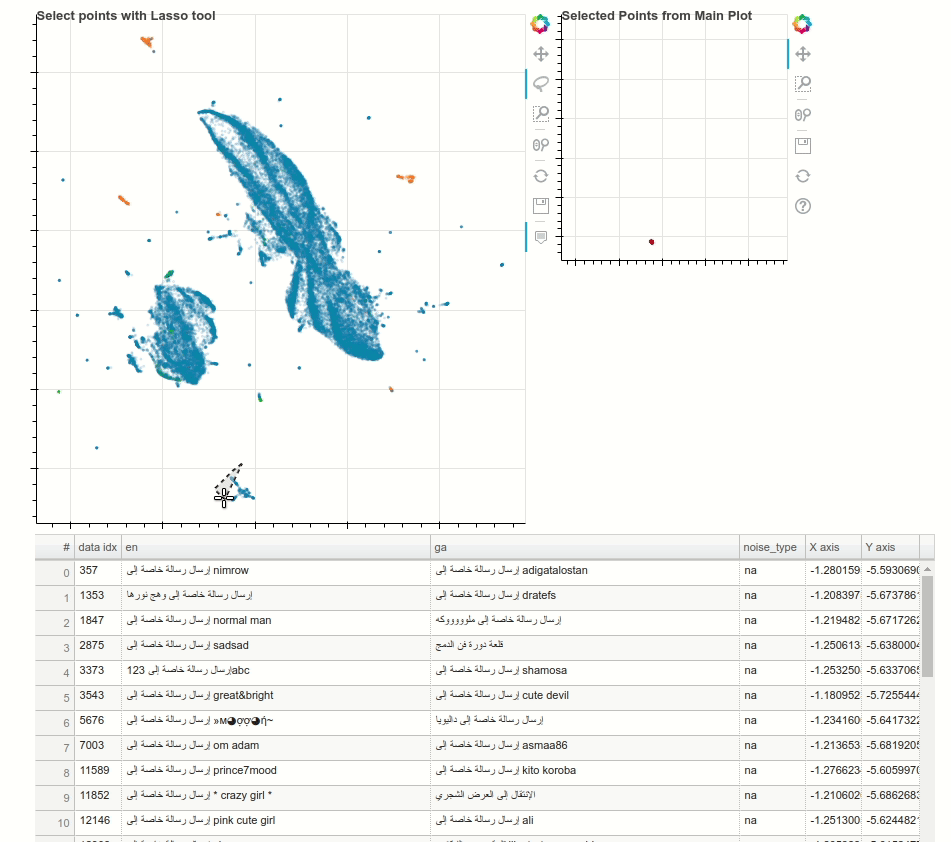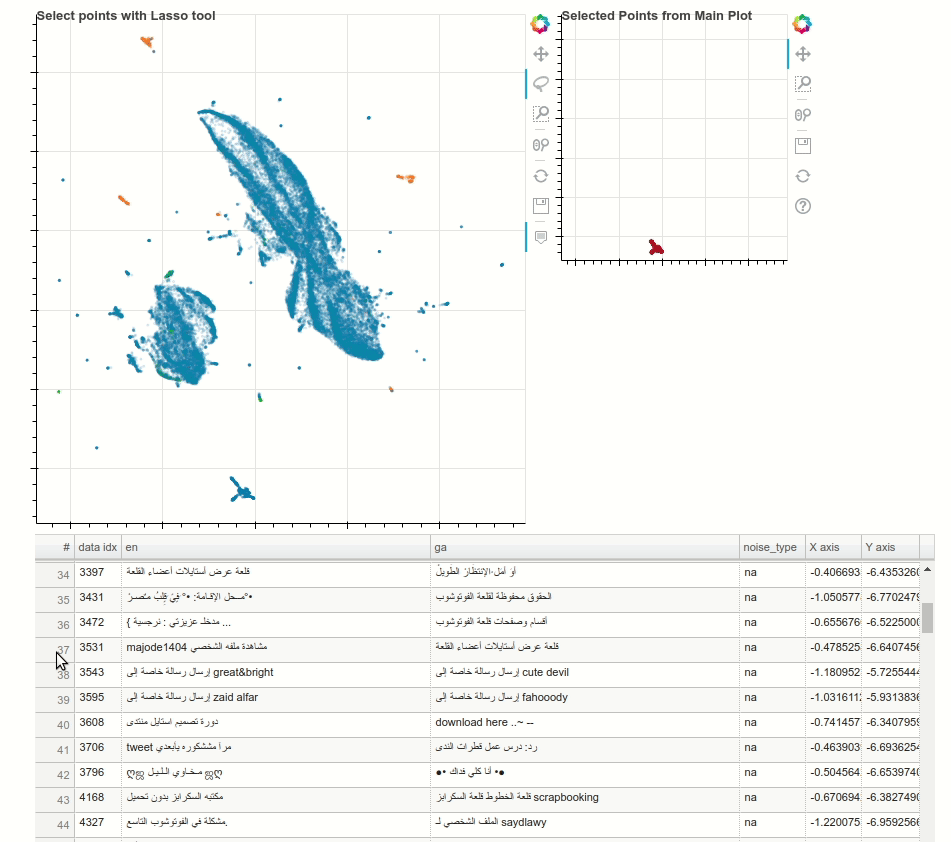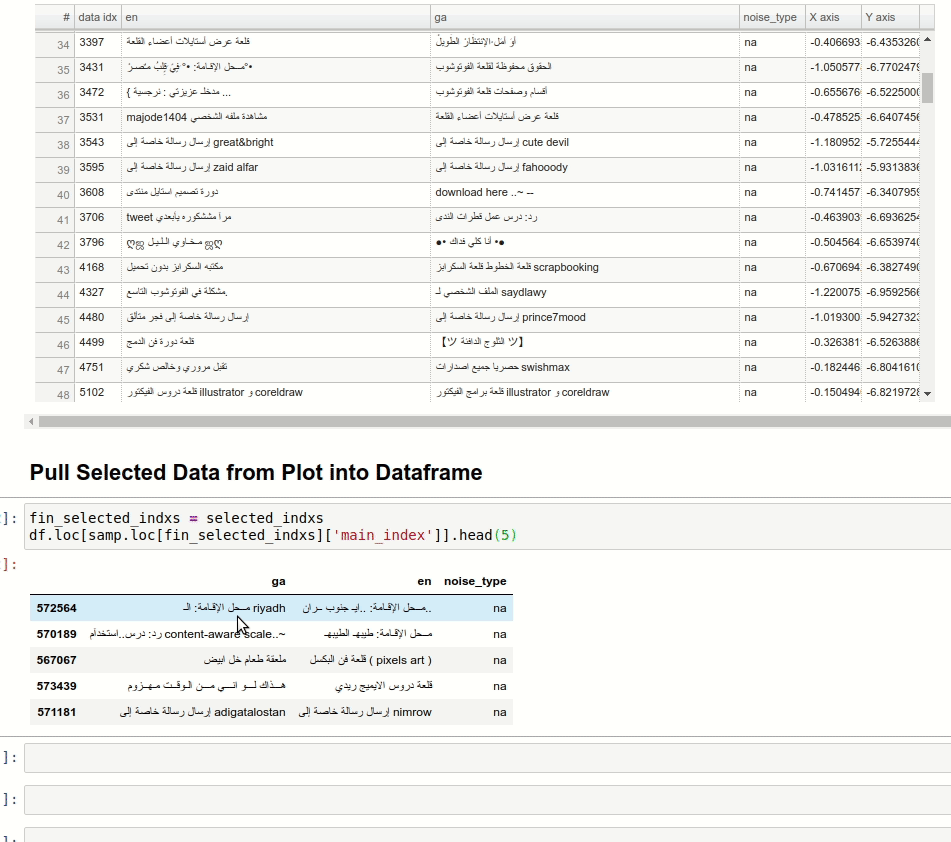{kind=link}
Education 🎓
Ethical & Responsible NLP
Rachel Tatman addresses important topics in her keynote What I won’t build at @WiNLPWorkshop. Researchers and practitioners should determine if the systems they build can cause harm, discrimination, or invade privacy. Rachel urges that we ask a series of questions about the users, usage of the system, and its effect on systemic inequality. She also advocates for educating others on the risks and how organizing a coordinated effort can show results.
Full Stack Deep Learning
This new course called Full Stack Deep Learning aims to provide the necessary knowledge needed to deploy deep learning models in production. Some topics covered in this free online course are how to set up machine learning projects, data management, training and debugging, testing and deployment, among other topics.
Reinforcement Learning Tutorial
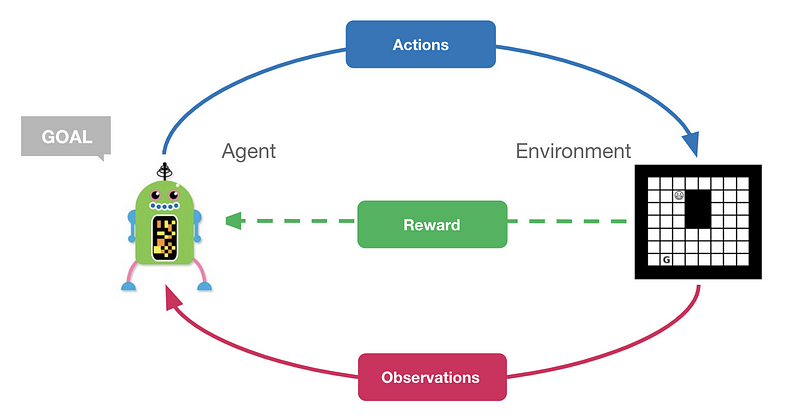
In this comprehensive reinforcement learning tutorial (available as a Google Colab), Feryal demonstrates important RL concepts which include algorithms like policy iteration, Q-Learning and Neural Fitted Q. In addition, a short introduction to deep reinforcement learning is also covered which includes explanations and code for the Deep Q-network (DQN) algorithm.
Stay Informed 🎯
If you are looking for further overviews and highlights from ACL this year the following links may interest you:
- Highlights of ACL 2020 (by Vered Shwartz)
- The missing pieces in virtual-ACL (by Yoav Goldberg)
- Takeaways from ACL 2020 Mentoring Session on Career Planning & becoming a research leader (by Zhijing Jin)
We would also like to suggest some ongoing challenges if you are looking for ideas to get started and apply NLP and machine learning in practice:
- Dravidian-CodeMix — sentiment analysis for Dravidian languages in the code-mixed text found in social media
- NLC2CMD — translate English descriptions of command-line tasks to their corresponding Bash syntax
- IEEE BigData 2020 Cup — a data mining challenge to predict escalations in customer technical support using natural language techniques
Noteworthy Mentions ⭐️
- Amit Chaudhary published an article that goes over challenges with the Word2Vec algorithm and how FastText solves those challenges by using sub-word information.
- In this blog post, George Ho summarizes the recent general trends in natural language processing. He provides a short summary of recent methods including other aspects of these models such as scaling and differences in representations.
- Kostas Stathoulopoulos built this search tool for exploring and discovering recent and past ACL papers. You can search for publications by author, the field of study, year, paper title, etc.
- cutlet converts Japanese to romaji. Unlike existing tools, it uses the same dictionary as a common Japanese tokenizer and has the option to use the original spelling for foreign loanwords.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.