

NLP Haber Bülteni’nin 9. sayısına hoş geldiniz. Umarız siz ve sevdikleriniz iyi ve güvendesinizdir. Bu sayı, mahremiyeti korumaya yönelik bir NLP aracından COVID-19’la ilgili bildirileri bulabilmek için geliştirilmiş etkileşimli araçlara ve çizge sinir ağları (İng. Graph Neural Networks) oluşturmaya yönelik illüstrasyon destekli bir kılavuza kadar uzanan konuları içermektedir.
Araştırma and Yayınlar 📙
Kendi-Yorumlayabilen Ajanların Nöroevrimi
Burada (Tang et al. 2020), bir görevi sürdürebilmek hedefiyle bir görsel girdi parçasından yararlanabilen bir ajan (İng. agent) geliştirmeyi amaçlayan (örn; aşağıdaki şekilde görüldüğü gibi virajları çarpmadan geçebilmek veya kurşunlardan kaçınabilmek için) ilginç ve yaratıcı bir çalışma sunuluyor. Çalışmayı yapanlar, girdilerin sadece bir parçasını kullanma kısıtı altında farklı görevleri icra edebilmek için takviyeli öğrenme (İng. reinforcement learning) ajanlarını, öz-dikkat (İng. self-attention) yapıları eğitebilmek için Nöroevrim’i (neuroevolution) kullanarak, eğitmeyi başardılar. Modelin faydaları arasında; parametrelerin boyutunda önemli bir azalma, hareket tarzı yorumlanabilirliği ve modelin sadece görev açısından kritik görsel ipuçlarının değerlendirmesini sağlamak yer alıyor.

RONEC’e Giriş: Rumence Varlık İsmi Derlemi
RONEC, Rumence için, 16 farklı sınıfa ait ~5000 açıklamalı cümlede 26000’den fazla varlık içeren bir varlık ismi derlemidir (İng. named entity corpus). Cümleler, çeşitli biçimleri kapsayan, telifsiz bir gazeteden alınmıştır. Bu derlem, Romen dili alanındaki, özellikle varlık ismi tanıma amaçlı ilk girişimidir. Derlemin BIO ve CoNLL-U Plus formatları da mevcut ve burada erişilen bu derlemi kullanmak ve genişletmek serbettir.
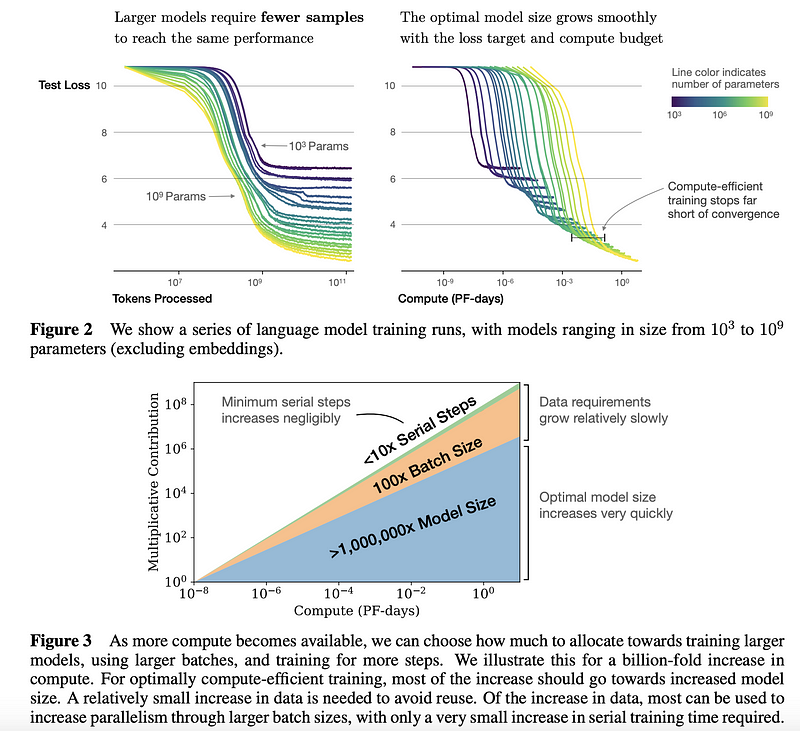
Yapay Sinir Modelleri İçin Ölçekleme Kanunları
John Hopkins ve OpenAI’den araştırmacılar, dil modeli performansı için ölçekleme yasalarını anlamak için ampirik bir çalışma yaptılar. Bu tür bir çalışma, kaynakların nasıl daha etkin kullanılacağı konusunda daha iyi kararlar almak için bir rehber niteliğinde. Genel olarak, daha büyük modellerin örneklem açısından belirgin şekilde daha verimli olduğu görülmüştü. Eğer veri veya hesaplamalar limitliyse, küçük bir modeli eğitmek yerine bir büyük modelin yakınsama (İng. converging) gerçekleşene kadar birkaç aşamalı şekilde eğitilmesi daha iyidir (aşağıdaki şekilde özetlenen sonuçlara göz atın). Araştırmacılar, aşırı öğrenme (İng. overfitting), optimum yığın (İng. batch) boyutu seçme, ince-ayarlama (İng. fine-tuning), mimari seçimi vb. açısından büyük dil modellerinin eğitimiyle ilgili (örn; Transformatörler) birçok bulgu ve öneri sunuyorlar.
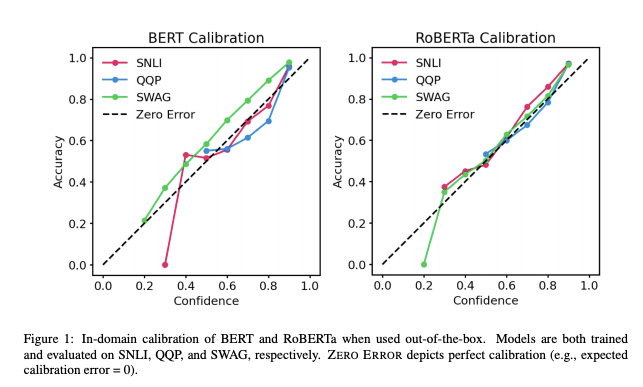
Ön-eğitime Tabi Tutulmuş Transformatörlerin Kalibrasyonu
Ön-eğitime tabi tutulmuş (İng. pre-trained) transformatörlerin (İng. transformers) pratik uygulamalarının artışıyla birlikte, bu transformatörlerin ne denli güvenilir çıktılar verdiklerini anlamak önem kazandı. UT Austin tarafından yapılan son çalışma, BERT ve RoBERTa’nın posterior olasılıklarının hem alan içi hem de alan dışı zorlu veri kümeleriyle üç görevde (doğal dil çıkarımı (İng. natural languge inference), yorumlama algılama (İng. paraphrase detection), sağduyulu akıl yürütme (İng. commonsense reasoning)) nispeten kalibre edildiğini (yani ampirik sonuçlarla tutarlı) göstermektedir. Sonuçlar şunu göstermektedir: (1) hazır olarak kullanıldığında, ön-eğitime tabi tutulmuş modeller alan içinde kalibre edilmiştir; ve (2) sıcaklık ölçeklendirme, alan içi kalibrasyon hatasını daha da azaltmada etkilidir, ampirik belirsizliği artırmak için etiket yumuşatma, posteriorları alan dışında kalibre etmeye yardımcı olur.
Derin Öğrenmenin İstatistiksel Mekaniği
Yakın tarihli bir bildiride fiziksel / matematiksel konular ile derin öğrenme arasındaki bağlantıya daha yakından bakılıyor. Araştırmacılar, istatistiksel mekanik ve makine öğrenimi ile kesişen daha derin konuları, derin sinir ağlarının teorik yönünü ve neden başarılı olduklarını anlamaya yardımcı olan soruları yanıtlamak amacıyla tartışmayı amaçlamaktalar.
Konuşmanın Metne Çevrimi’nde Bir ImageNet Başarımına Doğru
The Gradient’de yayımlanan yeni bir makalede Alexander Veysov Rus Dili bağlamında neden ImageNet başarımına ulaşılmış olabileceğine inandıklarını anlatıyor. Son birkaç yıldır, araştırmacılar NLP konusunda da benzer ifadelerde bulunuyorlar. Yine de, Konuşmanın Metne Çevrimi’nde (İng. Speech-to-Text) böyle bir başarıma ulaşmak için, Alexander, modelleri yaygın olarak kullanılabilir hale getirmek, hesaplama gereksinimlerini en aza indirmek ve ön-eğitime tabi tutulmuş büyük modellerin erişilebilirliğini artırmak gibi birçok parçanın bir araya gelmesi gerektiğini belirtiyor.
Yaratıcılık, Etik ve Toplum 🌎
COVID-19 İle İlgili Yayınları Taramak
Geçen hafta COVID’le ilgili bildirilerin bulunduğu CORD-19 olarak isimlendirilen herkese açık bir veri setinden bahsetmiştik. Gabriel Sarti, SciBERT ince-ayara tabi tutulmuş model‘inden yararlanarak, bu bildirileri daha iyi inceleyebilmeniz için etkileşimli bir araç geliştirdi. Araca buradan erişebilirsiniz.
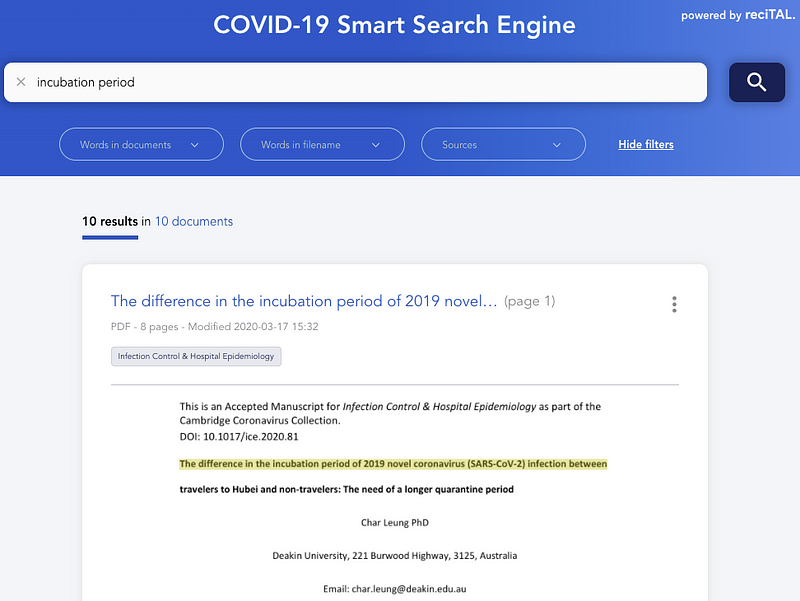
Diğer yandan reciTAL, araştırmacıların ve sağlık uzmanlarının COVID-19 ile ilgili bilgileri hızlı ve verimli bir şekilde bulmalarına ve keşfetmelerine yardımcı olmak amacıyla ilgili makalelerde arama ve göz atmaya özelleşmiş COVID-19 Akıllı Arama Motoru adlı bir proje de yayımladı.
SyferText
OpenMind, gizli veri setleri için mahremiyeti korumaya yönelik güvenli ve özel NLP işlemlerinin yapılmasını hedefleyen yeni NLP kütüphanesi SyferText‘i yayımladı. Çalışma henüz erken evrelerinde; ancak bunun daha etik ve güvenli AI sistemleri için harcanmış önemli bir efor olduğuna inanıyoruz. Başlamak için şurada birkaç rehber bulabilirsiniz.
Daha ucuz, daha hızlı ve daha çevreci NLP için daha küçük modellere doğru
Daha büyük modeller her zaman daha mı iyidir? Geçtiğimiz birkaç yıldaki dil modeli boyutlarının evriminine bakılırsa, bu soru evet diye cevaplanabilir; ancak bu canavarları eğitmenin finansal ve çevresel maliyeti oldukça yüksek. Ayrıca, bu durumda daha büyük genellikle daha yavaş anlamına gelmektedir ve hız birçok uygulamada hayati önem taşımaktadır. Bu da NLP’deki gidişatı, mevcut performansı korurken daha küçük, daha hızlı ve daha çevreci modeller için uğraşmaya motive etmektedir. Şu blog gönderisinde, Manuel Tonneau, küçük modelleri tercih eden bu yeni akımı, güncel ve popüler üç modele odaklanarak tanıtmaktadır: HuggingFace‘den DistilBERT, Google‘dan PD-BERT ve Microsoft‘tan BERT-of-Theseus.
Bilimsel keşif için Derin Öğrenme Üzerine Derleme
Günümüzde yapay zeka araştırmaları üzerine odaklanmış birçok şirket, derin öğrenmenin bilimsel keşiflerde bir araç olarak kullanılabileceğine inanmaktadır. Şu bildiri, farklı bilimsel kullanım senaryoları için yaygın olarak kullanılan derin öğrenme modelleri üzerine kapsamlı bir genel bakış sağlamaktadır. Aynı zamanda geliştirme ipuçları, rehberler, farklı araştırma özetleri ve araçlar da tanıtmaktadır.
Araçlar ve Veri Setleri ⚙️
TextVQA ve TextCaps
Görüntülerdeki metinleri daha iyi tespit edip okuyan modeller geliştirmeyi ve bu modelleri soru cevaplama, altyazı üretme (İng. caption geration) gibi işlemlerde kullanmayı teşvik etme amacıyla, Facebook AI iki adet yarışmaya ev sahipliği yapmaktadır. Yarışmaların isimleri TextVQA Challenge ve TextCaps Challenge; sırasıyla görsel soru cevaplama ve altyazı üretme görevlerine hitap etmektedirler.
KeraStroke
Bir sinir ağı tasarlarken üstesinden gelinmesi gereken en büyük güçlüklerden birisi aşırı öğrenmedir. Dropout, Regularization ve erken durdurma gibi güncel genelleştirme-geliştirme teknikleri birçok kullanım senaryosunda oldukça etkilidir; ancak büyük modeller ya da küçük veri setleri kullanıldığında yetersiz kalma eğilimindedirler. Bu duruma cevap olarak, Charles Averill, büyük modeller ya da küçük veri setlerinde oldukça kullanışlı yeni bir genelleştirme-geliştirme tekniği KeraStroke‘u geliştirdi. Bu teknik sayesinde eğitim esnasındaki belirli durumlarda ağırlık (İng. weight) değerlerini değiştirerek, modeller aldıkları eğitim verisine dinamik olarak adapte olabilmektedirler.
torchlayers
torchlayers, torch.nn modülünde bulunan evrişimli ağ (CNN), tekrarlayan ağ (RNN), transformatör vb. katmanlarının biçim ve boyutlarının otomatik anlamlandırılmasına olanak sağlayan PyTorch’un üzerine kurulmuş yeni bir araçtır. Bu sayede katmanlarda elle belirtilmesi gereken girdi özelliklerinin (İng. input features) boyutlarını açıkça tanımlamaya gerek kalmamaktadır. PyTorch’ta bir modelin tanımlanması oldukça basitleşmektedir. torchlayers ile gerçeklenmiş basit bir sınıflandırıcı örneğini aşağıda görebilirsiniz.

Kod parçasından görüldüğü üzere Linear katman hem output hem de input boyutunun aksine yalnızca output boyutunun belirtilmesine ihtiyaç duymaktadır. Input boyutu torchlayers tarafından otomatik bir şekilde çıkarılmaktadır.
Haystack: Farklı Ölçeklerde Soru Cevaplama için Açık Kaynaklı kütüphane
Haystack, farklı ölçeklerde soru cevaplama için transformatör modellerinin kullanılmasına olanak sağlamaktadır. Bulucu-Okuyucu-İşlem-dizisi’ni (İng. Retriever-Reader-Pipeline) kullanmaktadır. Bu yaklaşımda Bulucu, aday belgeleri bulan hızlı bir algoritma; Okuyucu ise cevabı parça parça çıkaran bir transformatördür. Elasticsearch ve HuggingFace’in Transformers kütüphanesi üzerine kurulmuştur. Açık kaynaklı, oldukça modüler ve kolay genişletilebilir bir yapıdadır.
Bir yapay zekaya haber makalelerini özetlemeyi öğretmek: Soyutlayıcı özetleme için yeni bir veri seti
Curation Corp 40.000 adet profesyonelce yazılmış haber makalesi özetlerini açık kaynak olarak kullanıma sundu. Bu makale, metin özetleme ve işlemin zorluklarına güzel bir giriş sağlamaktadır. Ek olarak, veri setini ve veri seti ile ele anılabilecek problemleri tanıtmaktadır, metin özetlemede değerlendirme metrikleri ve ince-ayar teknikleri üzerine bir tartışmayı içermektedir. Gelecek çalışmalar üzerine bir tartışma ile de makale sonlanmaktadır. Veri setine nasıl erişileceğine dair açıklamalar şu GitHub reposunda, veri setini ince-ayar işlemlerinde kullanmak için örnek çalışmalar da burada bulunabilir.
Metin özetleme konusunda, HuggingFace takımı Transformers kütüphanelerinin bir parçası olarak BART ve T5‘i eklediler. Bu eklemeler soyutlayıcı özetleme (İng. abstractive summarization), çeviri, soru cevaplama ve daha birçok NLP işleminin gerçeklenmesine olanak sağlamaktadır.
Makaleler ve Blog gönderileri ✍️
İllüstrasyon Destekli Çizge Sinir Ağları Rehberi
Çizge sinir ağları son zamanlarda ilaç kullanımının yan etkilerini tahmin etme ve bilgisayarla görü modellerinin başarımını artırma gibi birçok işlemde benimsenmiş vaziyettedirler. Şu yazıda, Rish, çizge sinir ağlarına(GNN) kullanışlı bir resimli rehber ortaya koymaktadır. (*dair.ai*‘da öne çıkanlar)
JAX ve Haiku ile Transformer’lara ince-ayar
Geçtiğimiz ay DeepMind, kendi TensorFlow yapay sinir ağı kütüphaneleri olan Sonnet’in JAX versiyonu Haiku’yu açık kaynaklı olarak kullanıma sundu. Şu gönderi ön-eğitime tabi tutulmuş RoBERTa modelinin JAX + Haiku’ya açılan kapısı olan kaynak kodun üzerinden geçmektedir. Ardından modeli ince-ayara tabi tutarak bir alt görevi(İng. downstream task) çözmeyi göstermektedir. Gönderinin, düşük maliyetli nesne tabanlı modüllerin JAX’ın fonksiyonel programlama kısıtlamaları bağlamında kullanılmasına olanak sağlamak için Haiku’nun ortaya koyduklarından faydalanmayı gösteren kullanışlı bir rehber olması amaçlanmaktadır.
Doğal Dil İşleme vadisinde küçük bir gezinti: Metin önişleme ve Almanca
Flávio Clésio, Almanca’da NLP sorunlarıyla başa çıkarken karşılaşılan zorlukları anlatan oldukça detaylı bir makale yazdı. Yazısında, öğrendiği dersleri, nelerin işe yarayıp nelerin yaramadığını, birçok kabul görmüş en iyi tekniğin tartışmasını, kaçınılması gereken yaygın hataları ve bildiriler, bloglar gibi tonlarca öğrenme kaynakları paylaşmaktadır.
Fransızca yapay zekaya ayak uyduruyor: FlauBERT, CamemBERT, PIAF
Geçtiğimiz birkaç ayda, ilgi çekici Fransızca NLP kaynakları geliştirildi. CamemBERT, FlauBERT ve PIAF(Pour une IA Francophone, Fransızca Konuşan bir AI için)’dan bahsetmekteyiz. İlk iki model ön-eğitime tabi tutulmuş dil modelleridir; sonuncu ise Fransızca soru-cevap(QA) veri setidir. Şu blog gönderisi, üç projeyi ve projelerin süreçlerinde karşılaşılan bazı zorlukları ele almaktadır. Kendi dillerinde farklı modeller üzerinde çalışan insanlar için güzel bir yazı ve rehber niteliği taşımaktadır.
BERT-tarzı dil modeli için özel sınıflandırıcı
Marcin, BERT-tarzı modeller üzerine kendi sınıflandırıcınızı(duygu sınıflandırıcı gibi) nasıl inşa edebileceğinizi anlatan harika bir rehber daha yazdı. Oldukça güzel bir rehber; çünkü rehber aynı zamanda modelin farklı kısımları için HuggingFace Tokenizer ve PyTorchLightning gibi modern kütüphaneleri nasıl kullanabileceğinizi de açıklamaktadır. Google Colab notebook’unu burada bulabilirsiniz.
Eğitim 🎓
Metin Verisi için Keşifsel Veri Analizi
Bu kod örneklerinde, Yonathan Hadar, metinsel verinin keşifsel analizi (İng. exploratory data analysis) üzerine birçok tekniğin üzerinden geçmektedir. Bu rehbere dair.ai’da yer vermemizin sebebi veri analizinde herhangi bir veri bilimciniin faydalı bulacağı kabul görmüş teknikleri detaylı bir şekilde anlatmasıdır. Metinsel veri ile uğraşacak birinin başlaması için oldukça iyi bir noktadır.
Doğal Dil İşlemede Gömmeler
Mohammed Taher Pilehvar ve Jose Camacho-Collados, “Embeddings in Natural Language Processing (Doğal Dil İşlemede Gömmeler)” adlı yeni gelecek kitaplarının ilk taslağını kamuya sundular. Kitabın ana odak noktası NLP alanında kullanılan en yaygın teknikleri temsil eden gömme konseptini tartışmaktır. Yazarlar tarafından belirtildiği üzere, kitap “vektör uzay modellerinin temelleri, daha güncel cümleye göre kelime gömmeleri ve ön-eğitime tabi tutulmuş modellere dayalı bağlamsal gömme (İng. contextual embedding) tekniklerini” içermektedir.
A Brief Guide to Artificial Intelligence(Yapay Zekaya Kısa Bir Rehber)
Dr. James V Stone, güncel AI sistemleri ve birçok görevi yerine getirmedeki başarımları hakkında kapsamlı bir genel bakış sağlamak amacıyla yeni kitabı “A Brief Guide to Artificial Intelligence(Yapay Zekaya Kısa Bir Rehber)”ı kısa süre önce yayımladı. Özetinde belirtildiği üzere: “kitap resmiyetten uzak bir tarzda, kapsamlı bir açıklayıcı sözlük ve ileride okunması gerekenlerin listesi ile yazılmıştır; bu da kitabı, hızla evrimleşen AI alanına ideal bir giriş aracı yapmaktadır.”.

Makine Öğrenmesi ve Derin Öğrenme Kursları
Sebastian Raschka, “Introduction to Deep Learning and Generative Models(Derin Öğrenme ve Üretken Modellere Giriş)” adlı kursunun iki bölümünü yayımladı. Ders notlarını ve materyallerini şu repoda bulabilirsiniz.
“Ayrık Diferansiyal Geometri (İng. Discrete Differential Geometry” alanındaki bu muhteşem derslere göz gezdirebilirsiniz.
Peter Bloem, VU University Amsterdam’da verdikleri Makine Öğrenmesi’ne giriş dersinin ders sunuları ve videolarını da içeren bütün ders müfredatını yayımladı. Konular, lineer modeller ve olasılıksal modellerden sıralı veri modellerine kadar uzanmaktadır.
CNN Yapısı — Uygulamaları
Dimitris Katsios, orijinal bildirilerde önerilmiş evrişimli sinir ağı (CNN) yapılarının nasıl gerçeklenebileceğini anlatan bir dizi harika rehber sağlamaktadır. Yazılarında, modelin yapısını çıkarma yeterliğinde, adım adım işlemleri diyagram ve kodlar ile paylaşırken CNN modellerinin nasıl gerçekleneceğini tarif etmektedir.
Bunlara da göz atın ⭐️
Bir önceki haber bülteninin orjinial halini şurada; çevirilerini ise şu GitHub reposunda bulabilirsiniz.
İki ay önce Luis Serrano’nun “Grokking Machine Learning(Grokking Makine Öğrenmesi)” adlı kitabına yayınlarımızda yer vermiştik. Luis’in kendi kitabı hakkındaki fikirlerini ve makine öğrenmesi alanında nasıl iyi bir eğitmen olduğunu anlatan hikayesini şuradan dinleyebilirsiniz.
İşte ilginize değebilecek birkaç haber bülteni: Sebastian Ruder’in NLP Haberleri, Made With ML(Makine Öğrenmesi ile Yapıldı, SIGTYP’in Haber Bülteni, MLT Haber Bülteni, Nathan’ın AI bülteni, vb…
Jupyter artık bir görsel hata ayıklayıcıya sahip. Bu sayede, popüler veri bilimi aracı genel amaçlar için daha kolay kullanılabilir olmaktadır.
Abhishek Thakur, modern makine öğrenmesi ve NLP tekniklerinin nasıl kullanılacağını kodların üzerinden geçerek gösterdiği harika bir YouTube kanalına sahip. Bazı videoları, BERT modellerine ince-ayar yaparak el yazısı karakterlerini sınıflandırmaktan bir makine öğrenmesi aracı inşa etmeye kadar uzanmaktadır.
Ünlü takviyeli/pekiştirmeli öğrenme profesörü ve araştırmacı David Silver, bilgisayar oyunlarına getirdiği çığır açan yenilikler için ACM Prize in Computing ile ödüllendirildi. David, Lee Sedol’u Go’da yenen Alpha Go takımına liderlik etmişti.
BERT ve word2vec gibi popüler NLP tekniklerinin çalışma prensipleri arasındaki farkları öğrenmek isteyenler için Mohd, bu yaklaşımlara harika, kolay ulaşılabilir ve detaylı genel bakış yazıları sağlamaktadır.
TensorFlow 2.2.0-rc-1 yayımlandı. ML modellerinde darboğaz olan noktaları tespit etmeye yardımcı olan Profiler ve bu modellerin nasıl optimize edileceğini gösteren rehberler gibi yenilikler içermektedir. Ayrıca, Colab da artık varsayılan olarak TensorFlow 2 kullanmaktadır.
Gabriel Peyré, ML optimizasyonu dersi için bir dizi kullanışlı not sağlamaktadır. Notlar, dışbükey analizi (İng. convex analysis), SGD(rastgele gradyan inişi), autodiff (otomatik diferansiyel), çok katmanlı algılayıcı (MLP) gibi konu başlıklarını içermektedir.
dair.ai sitesinden güncellemeler
-
Açık Bilim için İşbirlikçilere Çağrı: Açık bilime katkı yapmak isteyenlere çağrıda bulunmaktayız. İşlem dizimizde birçok ilgi çekici işbirliği konusu var. Davetiyelerimizi açık bilime katkıda bulunmak isteyen herkese ulaştırmak istiyoruz. Gönüllüler, yazarlar, eleştirmenler, editörler, geliştiriciler, konuşmacılar, araştırmacılar, proje sahipleri vb. aramaktayız. Bize katılın!
-
NLP Araştırmasında İlginç Olaylar Sayı #1: ICYMI, şu makalede, bazı NLP akımlarını ve konu başlıklarını, geçtiğimiz birkaç ayda yayımlanan ilginç ve önemli NLP bildirilerinin hangisini,nasıl ve neden seçtiğimizi özetlemeye odaklanarak vurgulamaktayız.
Eğer NLP Haber Bülteni’nin sonraki sayılarında paylaşmak istediğiniz veri seti, proje, blog, rehber veya bildiri varsa lütfen şu formu kullanarak direkt gönderiniz.
*🔖Gelen kutunuzda NLP Haber Bülteni’nin gelecek sayılarını görmek istiyorsanız buradan abone olabilirsiniz.