

欢迎阅读《 NLP通讯》第十期。 我们希望您身体健康,并保持安全。 在本期中,我们涵盖的主题涵盖了从语言模型的最佳实践到机器学习的可复制性,再到自然语言处理(NLP)的隐私和安全性。
dair.ai updates 🔬🎓⚙️
-
-为了帮助探索COVID-19开放研究数据集并从科学文献中获取见解,我们发布了notebook,其中介绍了使用开源工具和公开可用的预训练语言模型构建简单文本相似性搜索应用程序的步骤。
-
上周我们在 Open Data Science Conference上提供了关于“Deep Learning for Modern NLP”.
- 在过去的一周中,我们与社区成员一起发表了两篇文章。 一个是关于unsupervised progressive learning ,这是一个涉及代理的问题, 分析一系列未标记的数据向量(数据流),并从中学习表示形式。 第二篇article总结了一种使用ELMo进行引用意图分类的方法。
- 我们最近发布了notebook ,该书有助于提供有关如何针对情感分类任务微调预训练的语言模型的想法。
1、Research and Publications 📙
1.1 XTREME
Google AI和DeepMind的研究人员发布了一个有趣的多任务基准,称为XTREME,旨在评估语言模型的跨语言泛化能力,学习多语言表示形式。 基准测试benchmark对40种语言和9种不同的任务进行了测试,这些任务需要在语法或语义上对不同级别的含义进行推理。 本文还使用最新的模型为多语言表示提供基线结果,例如mBERT,XLM和MMTE。
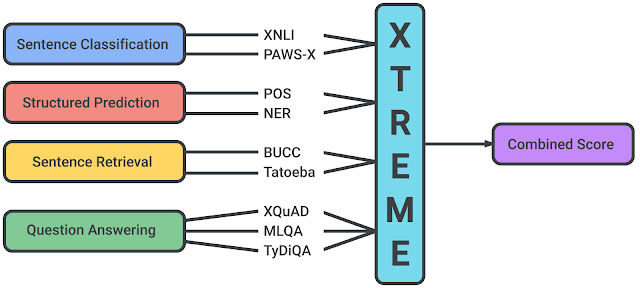
Source: Google AI Blog
\
1.2 通过实际语言评估机器
诸多研究表明,语言模型在诸如question answering和sequence labeling之类的各种任务上表现相对较好, 但是最近的论文,Evaluating Machines by their Real-World Language Use提出了一个框架和基准,以更好地评估语言模型是否可以在更复杂的设置下使用(例如,为当前情况生成有帮助的建议)。 经验结果表明,当前最先进的模型(例如T5)所生成的建议在仅9%的情况下与人工编写的建议一样有用。这些结果指出了LM在理解和建模世界知识和常识推理方面的缺陷。
1.3 给你的模型一点爱
与预训练的多语言版本相比,在特定于大型语言的数据集上训练单语言模型(例如FastText词嵌入和BERT)可以产生更好的结果吗? 在最近的一篇论文,Give your Text Representation Models some Love: the Case for Basque中,研究人员使用较大的语料库研究了相关模型的效果和性能。 结果表明,该模型确实在下游任务(例如主题分类,情感分类和Basque语PoS标记)上产生了更好的结果。 测试这y是否适用于其他语言,是否可能会产生一些有趣的结果或出现新的挑战,可能会很有趣。
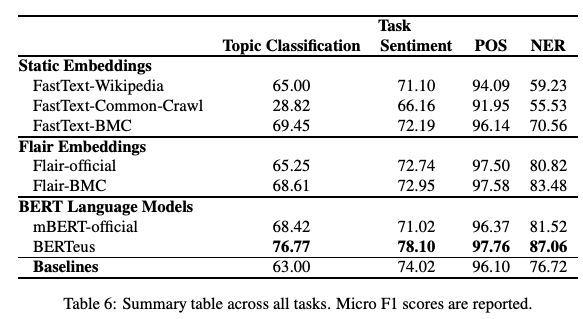
Figure by Agerri et al. (2020)
1.4 SimCLR改进自监督和半监督学习
在之前一期的NLP简报中,我们就介绍了SimCLR,它是Google AI提出了一种用于视觉表示的对比自我监督学习的框架,用于改善在诸如迁移学习和半监督学习等不同设置下的图像分类结果。 这是一种自我和半监督学习的新方法,可以从未标记的数据中学习视觉表示。 结果证明了它在ImageNet上获得了最先进的结果,而仅依赖1% 标记数据,表明该方法在资源匮乏的环境中也可能是有益的。
Source: Google AI Blog
值得一提的是,自监督学习是该领域的热门话题之一。 如果你想了解更多信息,可以查看以下内容:
- Computers Already Learn From Us. But Can They Teach Themselves?
- The Illustrated Self-Supervised Learning
- Self-supervised learning and computer vision
1.5 字节对编码在语言模型预训练中次优
Kaj Bostrom和Greg Durrett发表了一篇论文,,他们的目的是研究常用的称为字节对编码(BPE) 这一tokenization algorithm对于预训练语言模型(LM)是否是最优的。 换句话说,他们提出了tokenization对LM性能影响的直接评估。 根据作者的说法,之前的文献中很少对此进行研究。 为此,他们从零开始对LM进行了预训练,并应用了不同的tokenization,即unigram和BPE。 之后他们在几个下游任务上测试最终的预训练LM模型, 结果表明,unigram tokenization或优于更常见的BPE方式。
1.6 Longformer
Allen AI的研究人员发布了一种新的基于Transformer的模型,称为Longformer,该模型旨在更有效地处理较长的文本。 众所周知,基于transformer的模型局限性之一是它们的计算量很大,这是由于self-attention操作复杂度高(通常与序列长度成平方关系),从而限制了处理更长序列的能力。 最近,许多学者进行了各种尝试,例如Reformer和Sparse Transformers 等,以确保变压器的适用于长序列输入文本。 Longformer结合了字符级建模和self-attention(局部注意力和全局注意力的混合),以减少内存消耗并在长文档建模中证明其有效性。 作者还表明,将其训练后的模型应用于文档级下游任务(包括质量检查和文本分类)时,其性能优于其他方法。
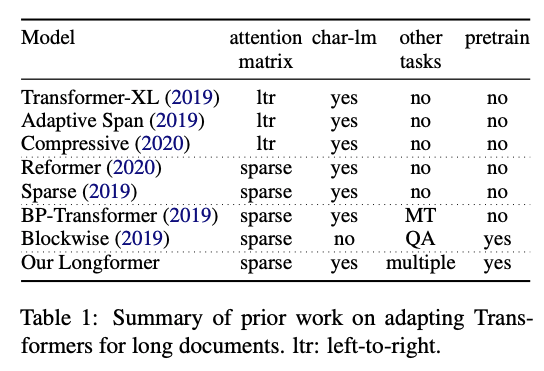
Figure by Beltagy et al. (2020)
2、Creativity, Ethics, and Society 🌎
2.1 ML的可复用性
-
在机器学习社区中,可重复性一直是一个被讨论的话题。 为了鼓励更加开放,透明和可访问的科学,围绕可重复性已进行了许多努力。如果你想了解机器学习领域在可重复性方面的地位,请查看Joelle Pineau等人的论文,Improving Reproducibility in Machine Learning Research。
-
最近,在先前这些工作的启发下,Papers With Code小组(现已成为Facebook AI的一员)发表了博客文章,ML Code Completeness Checklist, 有用的机器学习可重现性清单,以“ 促进在大型ML会议上提出的可重现性研究”。 该清单评估以下方面的代码提交:

Source: Papers with Code
- 关于开放科学和可重复性,这是NLP研究人员的一篇有趣的帖子,提供了赏金来复现另一位研究人员无法复现的论文结果。
2.2 NLP的隐私安全
通过API公开使用的预训练语言模型是否可以被盗,是否会对安全性有影响? 在一篇新论文中,Thieves on Sesame Street! Model Extraction of BERT-based APIs,研究人员旨在测试基于BERT的API的安全性。 他们发现,攻击者可以通过仅输入乱码并在受害者模型的预测标签上微调自己的模型来窃取微调的模型。更多有关model extraction attacks的信息,可以查看博客,如何用乱码窃取NLP系统?.
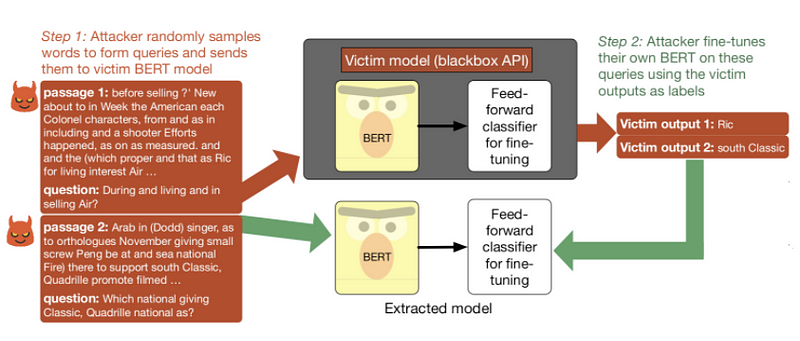
Model extraction pipeline applied to a victim model trained on SQuAD (Source).
在ACL 2020上接受的另一篇有趣的论文,Weight Poisoning Attacks on Pre-trained Models,研究了预训练的语言模型是否容易受到攻击。作者开发了一种“poisoning”方法,该方法能够将漏洞注入预先训练的权重中,从而使这些预训练模型容易受到严重威胁。由于存在此漏洞,有可能表明这些模型暴露了后门,攻击者可以通过简单地注入任意关键字来利用后门来操纵模型的预测。 为了测试这一点,使用了经过预训练的模型来执行下游任务,这些任务涉及注入了特定关键字的数据集,这些关键字旨在迫使模型对实例进行错误分类。
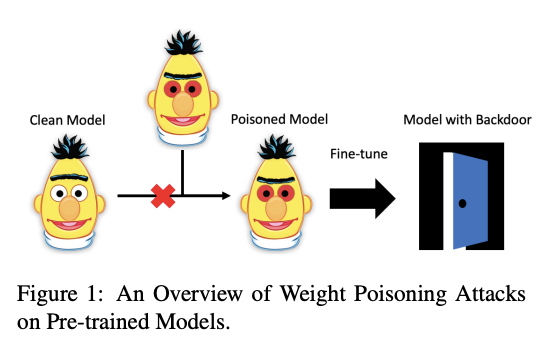
Figure by Kurita et al. (2020)
2.3 一系列基于AI的COVID-19应用和研究
-
事实证明,COVID-19是近来最大的挑战之一。从搜索引擎到公布数据集,世界各地的研究人员都在尝试寻找方法来帮助和理解COVID-19。Sebastian Ruder最近发表一份专门的issue,重点介绍了AI研究人员正在进行的一些关于COVID-19有趣的项目。
- 此外关于COVID-19,Allen AI的研究人员将在本月底举行的虚拟研讨会中讨论现在流行的COVID-19开放研究数据集(CORD-19)。
- 许多研究人员正在使用CORD-19数据集来构建NLP驱动的应用程序,例如搜索引擎。看看最近的这篇论文,Rapidly Deploying a Neural Search Engine for the COVID-19 Open Research Dataset,以搜索引擎实现为例,它可以帮助研究人员从学术文章中报告的结果中快速获得与CORD-19相关的信息。作者认为,这样的工具可以帮助为基于证据的决策提供依据。
- ArCOV-19是阿拉伯语COVID-19 Twitter数据集,涵盖了从2020年1月27日至2020年3月31日的数据(并且仍在进行)。 这是涵盖COVID-19的第一个公开发布的阿拉伯语Twitter数据集,其中包括约748k流行的推文(根据Twitter搜索标准)以及其中最受欢迎的子集的传播网络。 传播网络包括转发和会话线程(即回复线程)。ArCOV-19旨在为自然语言处理,数据科学和社交计算等多个领域研究提供帮助。
3、Tools and Datasets ⚙️
3.1 python机器学习
Sebastian Raschka,Joshua Patterson和Corey Nolet的出色论文,Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence,本身并不是工具或数据集,但它提供了有关机器学习技术趋势方面某些主要发展的全面概述,尤其是对于Python编程语言,
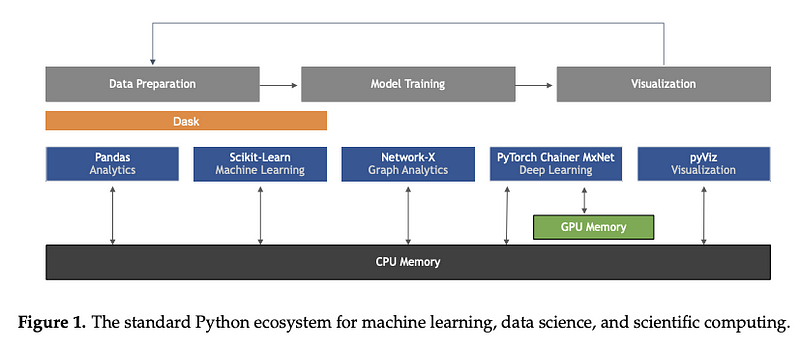
Figure by Raschka et al. (2020)
3.2 机器学习的可解释性
HuggingFace发布了一个名为exBERT的可视化工具,该工具可让你可视化从BERT和RoBERTa等语言模型中学到的表示。 此功能已集成到huggingface的模型页面中,旨在更好地了解语言模型是如何学习的以及它们在这些学习出的表示中可能encode的信息。
OpenAI最近发布了一个名为Microscope的Web应用程序,其中包含从各种视觉模型的重要层和神经元获得的可视化效果的集合,这些视觉效果通常是在可解释性的背景下进行研究的。 主要目的是使分析和共享有趣的见解变得容易,这些见解是从神经网络中学习到的这些特征中得出的,以便更好地理解它们。
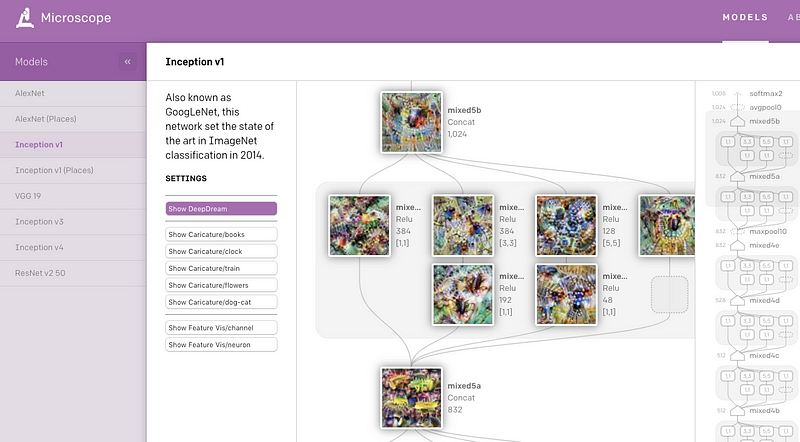
3.3 CloudCV
在先前的NLP Research HighLight中,我们介绍了多任务ViLBERT,这是一种改进视觉和语言模型的方法,该模型可用于基于字幕的图像检索和视觉问题解答(VQA)。 现在,作者提供了一个网站,CloudCV,以测试八种不同的视觉和语言任务(例如VQA和指向问题的答案)的模型。
3.4 COVID-19相关Twitter数据集
由于COVID-19全球性蔓延,研究人员正在发布从Twitter获得的与COVID-19聊天相关的推文的数据集。 从第一个版本开始,已添加了来自新协作者的其他数据,从而使该资源增长到当前的大小。 从3月11日开始,专用数据收集每天产生超过400万条推文。
3.5 Micrograd
Andrej Karpathy最近发布了一个名为micrograd的库,该库提供了使用简单直观的界面来构建和训练神经网络的功能。 实际上,他用大约150行代码编写了整个库,他声称这是目前市面上最小的autograd引擎。
4、Articles and Blog posts ✍️
4.1 Transformer Family
在最近的博客文章中,Lilian Weng总结了Transformer模型的最新发展。该文章提供了很好的注释,历史回顾以及最新的改进,例如更长的注意力跨度(Transformer XL),减少计算量和内存消耗。
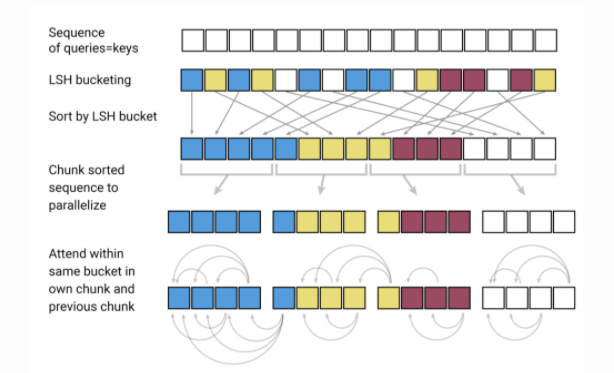
由于预训练语言模型的性质和规模较大,模型压缩是NLP研究的重要领域。理想情况下,随着这些模型继续在各种NLP任务中产生最先进的结果,减少它们的计算需求以使其在工业中可行变得很重要。 Madison May最近发表了一篇优秀的文章,总结了用于模型压缩 的几种方法,特别是在NLP中,主题包括修剪,图优化,知识蒸馏,渐进式模块替换等。
5、Education 🎓
5.1 语言模型讲座
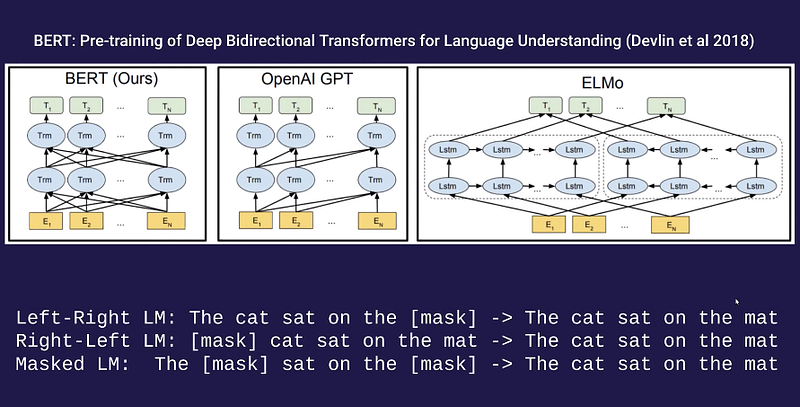
如果你想了解用于学习语言模型(例如CBOW,Word2Vec,ELMo,GPT,BERT,ELECTRA,T5和GPT)等方法的理论方面,那么你可能会对 OpenAI研究员Alec Radford的这个客座演讲感兴趣。这是Pieter Abbeel正在进行的关于深层无监督学习课程的一部分。
5.2 Python Numpy教程
斯坦福大学流行的在线课程, Convolutional Neural Network for Visual Recognition,现在包括Google Colab的链接。 这是一个非常广泛的教程,但对初学者来说非常好。
5.3 New mobile neural network architectures
如果你有兴趣为移动设备和边缘设备构建神经网络架构,那么这份综合博客文章可能适合你,New mobile neural network architectures,涵盖了一系列神经网络设计,并包括速度性能测试。
5.4 数据驱动的句子简化
句子简化旨在修改句子,以使其更易于阅读和理解。这一份综述文章,Data-Driven Sentence Simplification: Survey and Benchmark,侧重于尝试学习如何使用对齐的原始简体句子对的语料库来简化英语的方法。它还包括对通用数据集的不同方法的基准,以便进行比较并突出其优势和局限性。
5.5 机器学习高级主题
Yisong Yue发布了数据驱动算法设计课程的所有讲座视频。它包含了机器学习的高级主题,从贝叶斯优化到微分计算再到imitation learning。
6、Noteworthy Mentions ⭐️
哈佛目前正在免费提供许多自定进度的课程。
ARBML提供了许多阿拉伯语NLP和ML项目的实现,它们使用Web,命令行和笔记本等许多界面提供了实时体验。
NLP Dashboard是一个有趣的NLP Web应用程序,基于spaCy,Flask和Python构建,用于执行命名实体识别以及文本和新闻报道的统计分析。
如果你还没有注意到,Connor Shorten维护了这个非常有用的YouTube频道,他在其中总结了有趣的最新ML论文,介绍了每项工作的重要细节,同时提供了简短而简洁的摘要。此外,他还与该领域的其他杰出研究人员一起开了播客。
这是一个内容丰富而令人印象深刻的github库,它通过代码和注释为许多NLP场景提供了最佳实践和建议,例如文本分类,文本蕴含,文本摘要,问答等。
如果您希望在下一期NLP新闻通讯中共享任何数据集,项目,博客文章,教程或论文,请直接填写这份问卷.
Subscribe🔖至NLP新闻通讯,以在收件箱中接收以后的新闻。