
NLP Newsletter #2 [EN]: Reformer, DeepMath, ELECTRA, TinyBERT for Search, VizSeq, Open-Sourcing ML,…

Welcome back to the NLP Newsletter! 👋 This second issue covers topics that range from model interpretability to protein folding to active transfer learning. You can find the Markdown version of this edition towards the end.
Publications 📙
On trusting model’s uncertainty
A recent paper from Google AI, published at NeurIPS, looks at whether a model’s probabilities reflect its ability to predict out-of-distribution and shifted data. Deep ensembles were found to perform better (i.e., improved model uncertainty) on the dataset shift while other models did not become increasingly unsure with dataset shift, but instead became confidently wrong. (Read the paper here and the summary here.)

image corruption — source
Systematic generalization
An interesting work published in ICLR presents a comparison between modular models and generic models and their effectiveness for systematic generalization in language understanding. Based on a reasoning evaluation performed on a visual question answering task, the authors conclude that there may be a need for explicit regularizers and priors to achieve systematic generalization.
An efficient transformer-based model called Reformer
It is well known that a Transformer model is quite limited in the context window it can cover due to the expensive computations performed in the attention layer. Thus, it may only be possible to apply the Transformer model to limited text sizes or generate short statements or pieces of music. GoogleAI recently published an efficient variant of a Transformer model called Reformer. The main focus of this method is to be able to deal with much higher context windows while at the same time reducing computational requirements and improving memory efficiency. Reformer uses locality-sensitive-hashing (LSH) to group similar vectors together and creates segments out of them, which enable parallel processing. The attention is then applied to these smaller segments and corresponding neighboring parts — this is what reduces the computational load. Memory efficiency is accomplished using reversible layers that allow the input information of each layer to be recomputed on-demand while training via backpropagation. This is a simple technique that avoids the model of the need to store activations in memory. Check out this Colab notebook to see how a Reformer model can be applied to an image generation task.
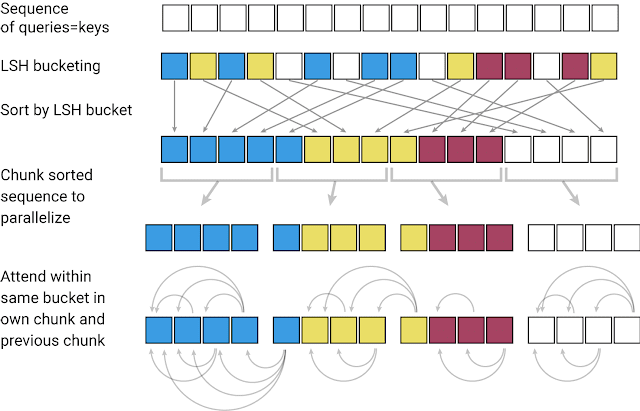
“Locality-sensitive-hashing: Reformer takes in an input sequence of keys, where each key is a vector representing individual words (or pixels, in the case of images) in the first layer and larger contexts in subsequent layers. LSH is applied to the sequence, after which the keys are sorted by their hash and chunked. Attention is applied only within a single chunk and its immediate neighbors.” — source
Unsupervised Domain Adaptation for Text Classification
This work proposes a combination of distance measures incorporated into an additional loss function to train a model and improve unsupervised domain adaptation. The model is extended to a DistanceNet Bandit model that optimizes results “for transfer to the low-resource target domain”. The key problem being addressed with this method is how to deal with the dissimilarity between data from different domains, specifically as it relates to NLP tasks such as sentiment analysis.
Improved Contextualized Representations
This paper proposes a more sample-efficient pretraining task called token detection for training a language model that is more efficient than masked language modeling pretraining methods such as BERT. The model is coined ELECTRA and its contextualized representations outperform those of BERT and XLNET on the same data and model size. The method particularly works well on the low-compute regime. This is an effort to build smaller and cheaper language models.
Model Interpretability
Distill recent publication titled “Visualizing the Impact of Feature Attribution Baselines” discusses integrated gradients that are used to interpret neural networks in various problems by identifying which features are relevant to predict a certain data point. The problem is to properly define and preserve a notion of missingness which is what the baseline input of integrated gradients is intended for. The challenge here, in the context of model interpretability, is that the method must ensure that the model doesn’t highlight missing features as important while at the same time avoiding giving the baseline inputs zero importance which can easily happen. The author proposes to quantitatively evaluate the different effects of some previously used and proposed baseline choices that better preserve the notion of missingness.
Creativity and Society 🎨
Sentiment mismatch
This longitudinal study finds that emotion extracted via the use of text-based algorithms are often not the same as the self-reported emotions.
Dopamine understanding and protein folding
DeepMind recently released two interesting papers in Nature. The first paper aims to better understand how dopamine in the brain works using reinforcement learning. The second paper is more related to protein folding and trying to understand it better to be able to potentially discover treatments for a wide range of diseases. These are great examples of how AI systems could potentially be applied to real-world applications to help society.
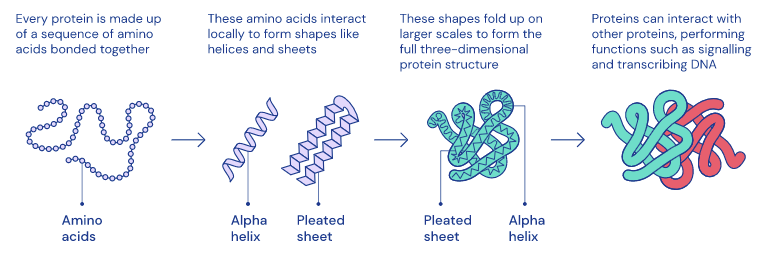
“Complex 3D shapes emerge from a string of amino acids.” — source
Interviews about ML in society
In an interview with Wired, Refik Anadol discusses the potential of machine learning algorithms to create beautiful art. This is an excellent example of how ML can be used for creativity.
One of the sectors where AI could have a major impact is in education. In a new episode, which is part of “The Future of Everything”, Russ Altman and Emma Brunskill have a deep discussion about computer-assisted learning.
Tools and Datasets ⚙️
PyTorch models in production
Cortex is a tool to automate the infrastructure and deploy PyTorch models as APIs in production with AWS. Learn more about how it’s done here.
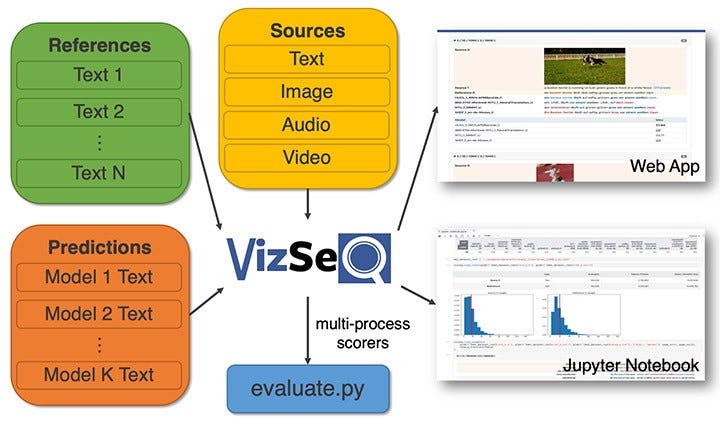
Visualizing Text Generation Sequences
Facebook AI released VizSeq, a tool that aids in visually assessing text generation sequences under metrics like BLUE and METEOR. The main goal of this tool is to provide a more intuitive analysis of text datasets by leveraging visualizations and making it more scalable and productive for the researcher. Read the full paper here.
State-of-the-art online speech recognition
FacebookAI open-sources wav2letter@anywhere which is an inference framework that is based on a Transformer-based acoustic model for state-of-the-art online speech recognition. Major improvements are around the model size and reducing latency between audio and transcription, which are both important to achieving faster real-time inferencing.
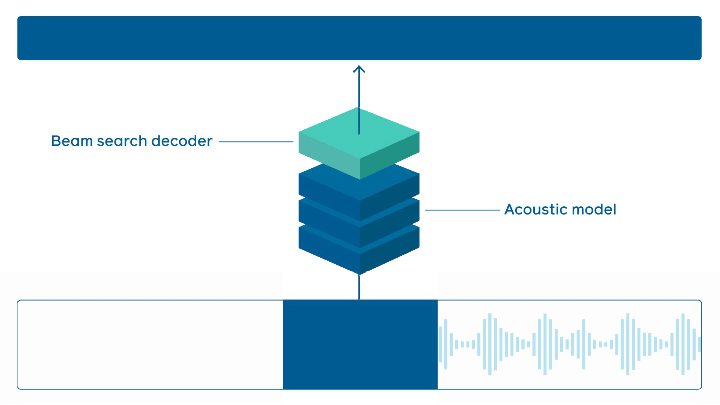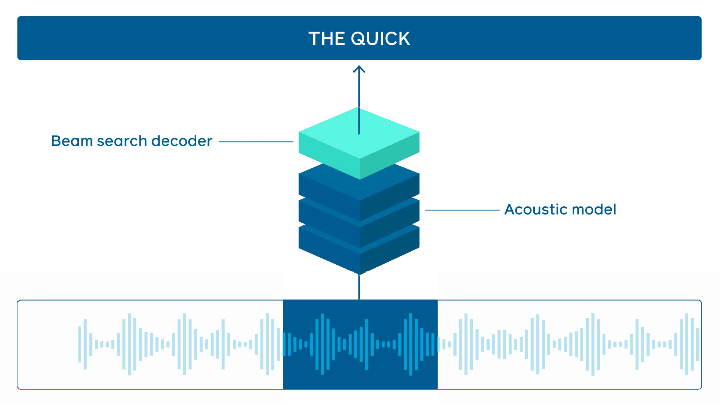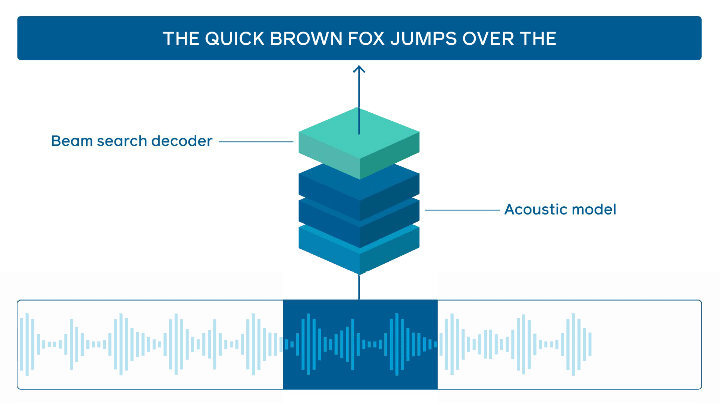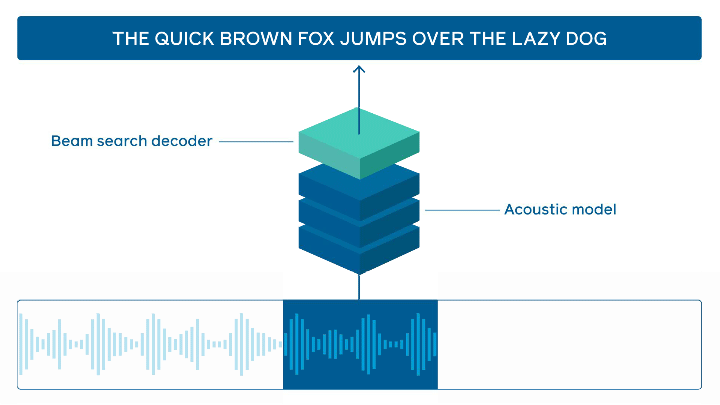
speech processing — source
Ethics in AI 🚨
AI implications
In an effort to prevent abuses and unethical actions of AI systems on the public, the European Union is considering to ban facial recognition technology from the public for five years. (Full story)
Environmental costs of modern NLP
Perhaps overlooked most of the time, this paper discusses the energy and policy considerations for modern deep learning approaches in NLP. It’s widely known that current models rely on billions of parameters and in turn large computational resources arising in a substantial consumption of energy. The authors hope to spread more awareness about the environmental costs involved in training these modern NLP models.
Zachary Lipton discusses fairness, interpretability, and the dangers of solutionism in this lecture delivered at the University of Toronto. The main topics revolve around careful considerations and implications of ML fairness approaches.
Articles and Blog posts ✍️
Open-Sourcing ML
Thomas Wolf, science lead at Hugging Face, shares excellent advice for those planning to open-source ML code or research. Find the Twitter thread here.
Intro to self-supervised learning for computer vision
Jeremy Howard wrote this great blog post briefly introducing the concept of self-supervised learning in the context of computer vision. I love these short summaries as they help to give you a reliable introduction in case you are interested in applying techniques from this domain to your own problem.
TinyBERT for search
We have already seen the success of many variants of BERT models (e.g., DistilBERT) that use some form of knowledge distillation to substantially decrease the model size and improve speed. A few folks used a variant of BERT called, TinyBERT, and applied it to a keyword-based search solution. This project was inspired by this search solution for understanding searches proposed by Google. The great part of the architecture is that it works on a standard CPU and can be used to improve and understand search results.
Active Transfer Learning
Rober Monarch wrote this excellent blog post about active transfer learning which is part of his upcoming book, Human-in-the-loop Machine Learning. He is currently writing great blog posts on methods for combining human and machine intelligence to solve problems. He also provides accompanying PyTorch implementations of the methods discussed.
Revealing the Dark Secrets of BERT
Anna Roger wrote this fun and interesting blog post which talks about what really happens with a fine-tuned BERT and whether the claimed strengths are used to approach downstream tasks such as sentiment analysis, textual entailment, and natural language inference, among others. The findings of the proposed analyses suggest that BERT is severely overparameterized and that the identified benefits of the self-attention component of the framework may not necessarily be as claimed in particular as it relates to the linguistic information that’s being encoded and used for inferencing.
Education 🎓
Neural Nets for NLP
Graham Neubig, NLP professor at CMU, has been releasing videos for the “Neural Nets for NLP” class being delivered this semester. I highly recommend this playlist for those interested in learning about modern NLP methods.
Deep Learning Math (DeepMath)
Want to dive deep into the mathematics behind deep learning methods? Here is a video lecture series hosting a wide range of speakers.
Python Courses and Tutorials
Python has become one of the most in-demand programming languages not only in the IT industry but also in the data science space. In an effort to equip learners from all over the world with practical knowledge of Python, Google released the “Google IT Automation with Python Professional Certificate.” Find out more about the release here and the course here. Although the course is not directly related to ML or AI, it’s definitely a nice foundational course to get proficient with the Python language. Scholarships are also available.
Here is another promising video series called “Deep Learning (for Audio) with Python” with a focus on using Tensorflow and Python for building applications related to audio/music by leveraging deep learning.

Andrew Trask released a set of step-by-step notebook tutorials for achieving privacy-preserving and decentralized deep learning. All notebooks contain PyTorch implementations and are meant for beginners.
Deep Learning State of the Art
Check out this video lecture by Lex Fridman on the recent research and development in deep learning. He talks about major breakthroughs on topics such as perceptrons, neural networks, backpropagation, CNN, deep learning, ImageNet, GANs, AlphaGo, and the more recent Transformers. This lecture is part of the MIT Deep Learning Series.
Online learning and researching
There are many great online initiatives to collaborate in research and learning. My personal favorites are the MLT’s math reading session and this new distributed AI research collaboration effort started by nightai. Recently, there have been many study groups like this online and they are great ways to immerse in the world of ML.
The landscape of Reinforcement Learning
Learn from Dr. Katja Hofmann the key concepts and methods of reinforcement learning and where it’s headed in this webinar series.
Notable Mentions ⭐️
Check out this clean and self-contained PyTorch implementation of ResNet-18 applied to CIFAR-10 which achieves ~94% accuracy.
PyTorch 1.4 is released! Check out release notes here.
Elona Shatri wrote this excellent summary about how she intends to approach optical music recognition using deep learning.
The title for this blog post is self-explanatory: “The Case for Bayesian Deep Learning”.
Chris Said shares his experience in optimizing sample sizes for A/B testing, an important part of practical data science. Topics include the costs and benefits of large sample sizes and best practices for practitioners.
Neural Data Server (NDS) is a dedicated search engine for obtaining transfer learning data. Read about the method here and the service here.