
While the best performing NLP models grow beyond the 10s of billions of parameters does the idea of knowledge distillation become more and more interesting. The idea is simple: let a massive, state-of-the-art model act as a teacher for a much smaller student model of similar architecture with the goal of replicating its behaviour. Implementing this in practice is what is interesting. If you want some context for the techniques and ideas presented in this article, please have a look at my article summarising DistillBERT which will be used as a baseline comparison here. (Spoilers, TinyBERT crushes DistillBERT in every metric imaginable)
In TinyBERT: Distilling BERT for natural language understanding, Jiao et al. present ideas and techniques that enable distillation of transformer based models in particular. Architecture-specific methods such as these ones enable even more of the knowledge captured by a teacher model to be transferred to its student.
Contributions of TinyBERT
The authors of TinyBERT introduce three new techniques: 1) transformer distillation, 2) a two step distillation process and 3) data augmentation. Together, these improve the knowledge distillation process in the particular case of transformer based models.
Transformer distillation
Their first contribution is what is call Transformer distillation, a set of loss functions designed to help the student learn from its teacher at a fine-grained level. These allow the student to observe how the teacher’s embedding layer, attention matrices, hidden representations and prediction layer react given some input text. Here are the mathematical formulations of these:
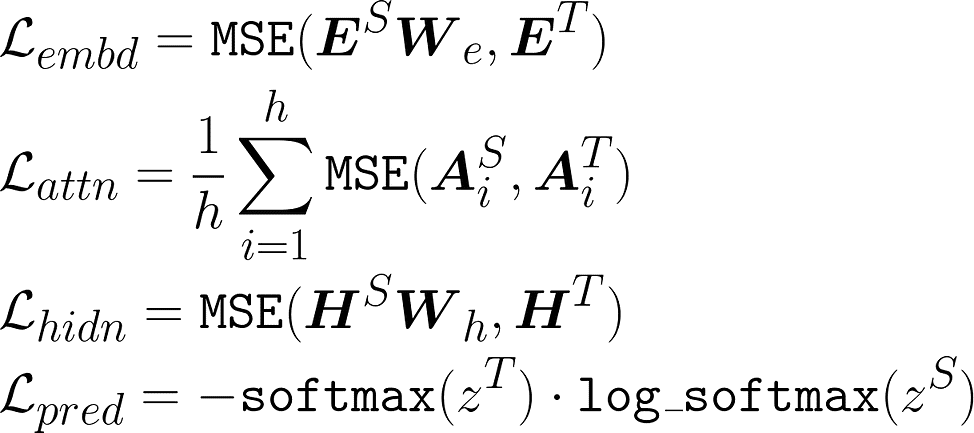
Previous work such as DistillBERT only trained the student to replicate the teacher based on its output distribution which in comparison greatly reduces the knowledge transfer. DistillBERT also used the teacher model for initialising the weight the student, which required both to have the same internal dimensions while allowing different number of layers. TinyBERT circumvents this issue by introducing learnable projection matrices (W) in both embedding and hidden loss functions. This allows the internal representations of student and teacher to be compared element-wise despite their difference in dimensions.
Side note: In What Does BERT Look At?, Clark et al. studies of what the attention heads of a pre-trained BERT learns to attend to and find that many different linguistic relations are captured. They also find that many attention heads learnt to attend the [SEP] token. A quantitative analysis of this phenomena is presented with the interesting conclusion: attending the [SEP] token is most likely a No-Op, meaning that it does not bring any value. This observation could be an indication of the fact that large BERT models are overparameterised. It would be interesting to perform the same analysis on TinyBERT or maybe to disregard attention heads with this behaviour in the distillation process.
Two-step distillation
In addition to the transformer specific distillation did the authors also introduce a two-step distillation process. It follows the procedure of how the original BERT was initially pre-trained on a large, general dataset to capture language features, to then be fine-tuned on task specific data. These steps are replicated in a distillation context.
Their first distillation step is therefor to utilise a general BERT, only trained on general data, as the teacher. The student learns to mimic the teacher’s embedding and transformer layer activations to create a General TinyBERT. The data used as this step is similar to that used to train the teacher BERT in the first place, something topic agnostic such as wikipedia.
The fine-tuning step switches teacher models to a task specific one and continues to train the student. Initially, the training is limited to embedding and transformer layers, keeping the prediction layer fixed which eventually is unfrozen and trained for a smaller number of steps. The data that was used during this distillation step is explained by their third contribution in the next section.
Data augmentation
To understand the authors choice of data for the fine-tuning step requires a holistic view of knowledge distillation. The goal of this process is to transfer the response, both internal and external, to an input from a teacher to a student. What exactly is used to probe the teacher’s response is of less importance. (If you want to listen to the authors of DistillBERT talk about this, then I highly recommend this podcast episode which does just that.)
Any data that tells us something about the teachers decision process is useful for distilling its knowledge.
The authors are because of this reason able to apply a clever data augmentation technique to expand their task specific dataset. They use a pre-trained BERT model (to replace sentence-piece tokens) and GloVe (for word-level tokens) to create alternate, highly probable versions of their input data. These are created through randomly selecting a subset of word/sentence-piece tokens from the dataset for which the helper models predict alternative tokens. For example, the sentence “how can anyone drive such a small car?” could be augmented into “how can anyone operate such a tiny vehicle”. Both these sentences would then be used in the fine-tuning distillation step!
Results
The authors define the student TinyBERT model equivalent in size to BERT small (4 transformer layers, hidden representation size 312, feed forward size 1200 and 12 attention heads. 14.5M parameters in total) and use BERT base as their teacher (12 transformer layers, hidden representation size 768, feed forward size 3072 and 12 attention heads. 109M parameters in total)
Using the proposed techniques enable this TinyBERT model to achieve 96% (76.5 vs 79.5 points average) of its BERT base teacher on the BLUE benchmark while being 7.5x smaller and 9.4x faster! Its performance numbers are impressive even when comparing with BERT small, a model of exactly the same size, which TinyBERT is 9% better than (76.5 vs 70.2 points average on GLUE).
TinyBERT is also able to outperform its related knowledge distillation models by a significant margin (76.5 vs 72.6 points average on GLUE), while in this case being approximately 3x smaller and faster than these. This is a testament to the importance of letting a student learn from the inner workings of its teacher, in addition to its output.
The authors analyse the effect of the different contributions in their work. There key take-aways are:
- Task specific distillation (fine-tuning) proves more important than general distillation (pre-training). This enables us to without hesitation use their pre-trained General TinyBERT for our own fine-tuning experiments.
- Data augmentation can be as important as task specific distillation in low resource tasks.
- Distilling knowledge from the transformer layers (attention and hidden representations) is by far the most important loss to minimise in order to achieve competitive results with the distilled model.
Conclusion
This paper introduce transformer specific distillation techniques which enable student networks of 14% the size of their teachers to achieve comparable performance results. These techniques are the logical evolution of ideas presented in related work such as DistillBERT, and prove themselves to be vital for distilling transformer knowledge.
It should, for any one interested, be exciting to follow how these ideas and methods find their way into even larger models!
Original. Reposted with permission.
About the author: Viktor Karlsson is a Machine Learning Engineer with a growing interest of NLP. Trying to stay on-top of recent developments within the ML field in general, and NLP in particular, with the goal of sharing knowledge and understanding to a wider audience.