

This paper aims to detect linguistic characteristics and grammatical patterns from speech transcriptions generated by Alzheimer’s disease (AD) patients.
The authors propose several neural models such as CNNs and LSTM-RNNs — and combinations of them — to enhance an AD classification task. The trained neural models are used to interpret linguistic characteristics of AD patients (including gender variation) via activation clustering and first-derivative saliency techniques.
Motivation
Language variation can serve as a proxy that monitors how patients’ cognitive functions have been affected (e.g., issues with word finding and impaired reasoning). This can equip machines with diagnostic capabilities, which are particularly effective for dealing with AD since it is neither curable or reversible.
Challenges and Limitations
The challenge with detecting AD-positive patients is it requires diverse linguistic and world knowledge. Consider the following example:
“Well…there’s a mother standing there uh uh washing the dishes and the sink is overspilling…overflowing.” There are several linguistic cues, such as “overspilling…overflowing”, indicating signs of confusion and memory loss, which is very common in AD-positive patients. Therefore, instead of relying on hand-crafted features, the authors propose a neural model for automatically learning these linguistic cues from the data. Other important issues observed from the previous literature are as follows:
- Hand-crafted features may not be suitable to analyze AD patients data, which convey progressive changes in linguistic patterns.
- Hand-crafted features quickly become outdated as language and culture evolve.
- Relying on neural networks alone doesn’t offer much interpretability.
Data
This work uses the Dementia Bank dataset, which consists of transcripts and audio recordings of AD (and control) patients. These records were collected via interviews on several tasks such as “Recall Test” and “Boston Cookie Theft”. Transcripts were segmented into individual utterances with accompanying part-of-speech (POS) tags.
Models
Three types of neural approaches are proposed: CNN (embedding + convolutional layer + max-pooling layer), LSTM-RNN (embedding + LSTM layer), and CNN-LSTM (basically laying an LSTM on top of CNN — architecture shown in the figure below). (See paper for more details.)

Results
The best performing model (POS tags + CNN-LSTM) achieves 91.1% accuracy, which sets a new benchmark for the AD classification task. See other results below.

The authors observed that almost all AD-positive results were classified correctly and that there were more errors in classifying non-AD samples. This could be because the dataset contained patients with various degree of symptoms related to AD. (See paper for more results.)
Analysis
No significant differences in linguistic patterns were observed between male and female AD patients.
Furthermore, interpretation of the linguistic cues captured by the neural models are conducted using two visualization techniques:
- Activation Clustering — offers insights into sentence-level patterns
- First Derivative Saliency — offers insights into word importance
Through the activation clustering, three common linguistic patterns found in AD patients emerged from the clusters: short answers and bursts of speech (e.g., “and” and “oh!”), repeated requests for clarification (e.g., “did I say fact?”), and starting with interjections (“so” and “well”). Moreover, for several tasks such as Cookie and Recall, the most commonly used POS tags for AD clusters were show to be distinct.
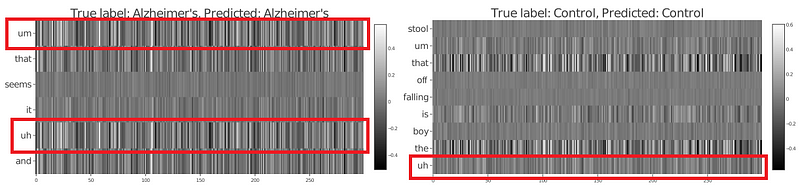
Through the salience heat maps, the difference in word importance can be seen between control and AD patients. As shown in the figure below (left), the word “uh” and “um” are important and distinguishable speech traits for classifying AD patients. The figure (right) shows that the control group does not heavily use these type of filler words.
Future Work and Conclusion
- Neural models combined with visualization techniques can offer more insights into the linguistic cues and variations of AD patients. With that said, such models can be generalized to study other neurological diseases.
- Context-aware models and conversational context can help to improve the predictive performance of the models and also offer more interpretability.
References
Detecting Linguistic Characteristics of Alzheimer’s Dementia by Interpreting Neural Models — (Sweta Karlekar, Tong Niu, and Mohit Bansal)